How Much Does Foundation Model Security Matter?

At the heart of every Generative AI application is the LLM foundation model (or models) used. Since LLMs are notoriously expensive to build from scratch, most enterprises will rely on foundation models that can be enhanced through few shot or many shot prompting, retrieval augmented generation (RAG), and/or fine-tuning. Yet what are the security risks that should be considered when choosing a foundation model?
In this blog post, we'll discuss the key factors to consider when choosing a foundation model.
The Core of LLM Applications
When assessing a foundation model, key factors include inference costs, parameter size, context window, and speed (time to first token). Take a look at Artificial Analysis and you'll be inundated with metrics on popular LLMs.
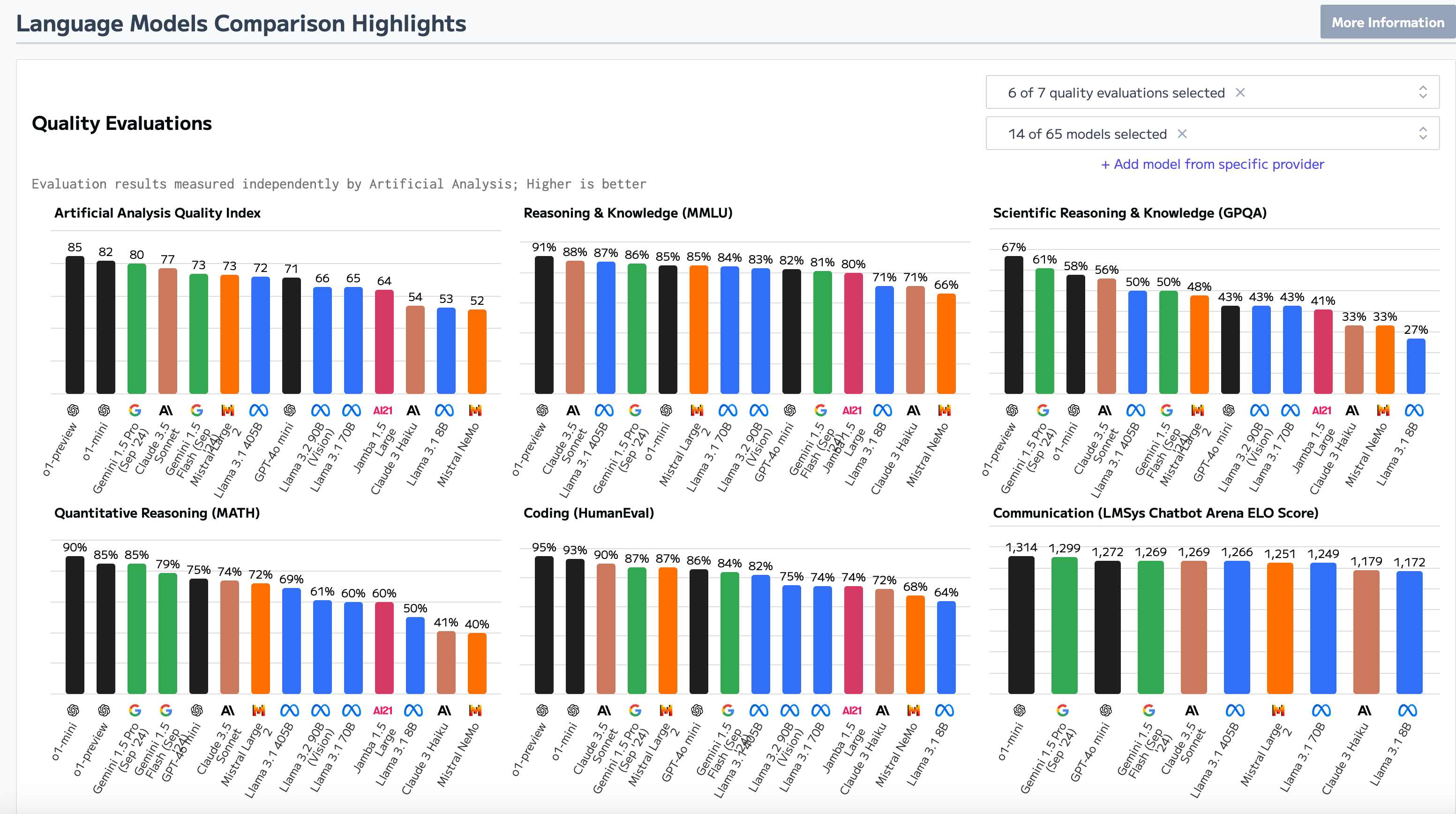
Beyond these metrics, it's essential to evaluate the safety and security risks of the model.
The first point of risk for a foundation model is the data used to train the base model. LLMs are trained on a vast corpus of data sources—public data, proprietary material, and synthetic data. Some LLM providers may also use user conversations to improve or train subsequent models.
The model's safety will be influenced by the quality of the data used to train it. For example, a model will behave differently when it is exclusively trained on Wikipedia articles compared to 4chan comments and erotic fiction.
Base models, which haven't undergone alignment, fine-tuning, or Reinforcement Learning from Human Feedback (RLHF), can pose additional risks. These models operate like an advanced auto-complete tool, making them less refined and potentially more dangerous than their fine-tuned counterparts. While base models do exist in the wild, most of us will engage with pre-trained LLMs that have undergone methodical fine-tuning to enhance performance and mitigate risk of harm.
Assessing Foundation Model Risk
An LLM's resilience to security and safety vulnerabilities is typically refined during RLHF, which will train the model to refuse harmful requests, accept benign requests, and behave as intended. Model developers must balance a fine line between creating versatile models that can be used for broader purposes, but may be more vulnerable to jailbreaking attacks, or models that are resistant to attacks but less flexible.
You can gain a sense of an LLM's performance and security through its system model cards. Model cards will provide useful information about an LLM's performance, the type of data it was trained on (and its cutoff date), and any safety evaluations that took place. For example, Llama 3.2's model card outlines its evaluations against CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons), child safety, and cyber attacks. You can view similar cards for OpenAI's latest o1 model and Anthropic's Claude 3 model family.

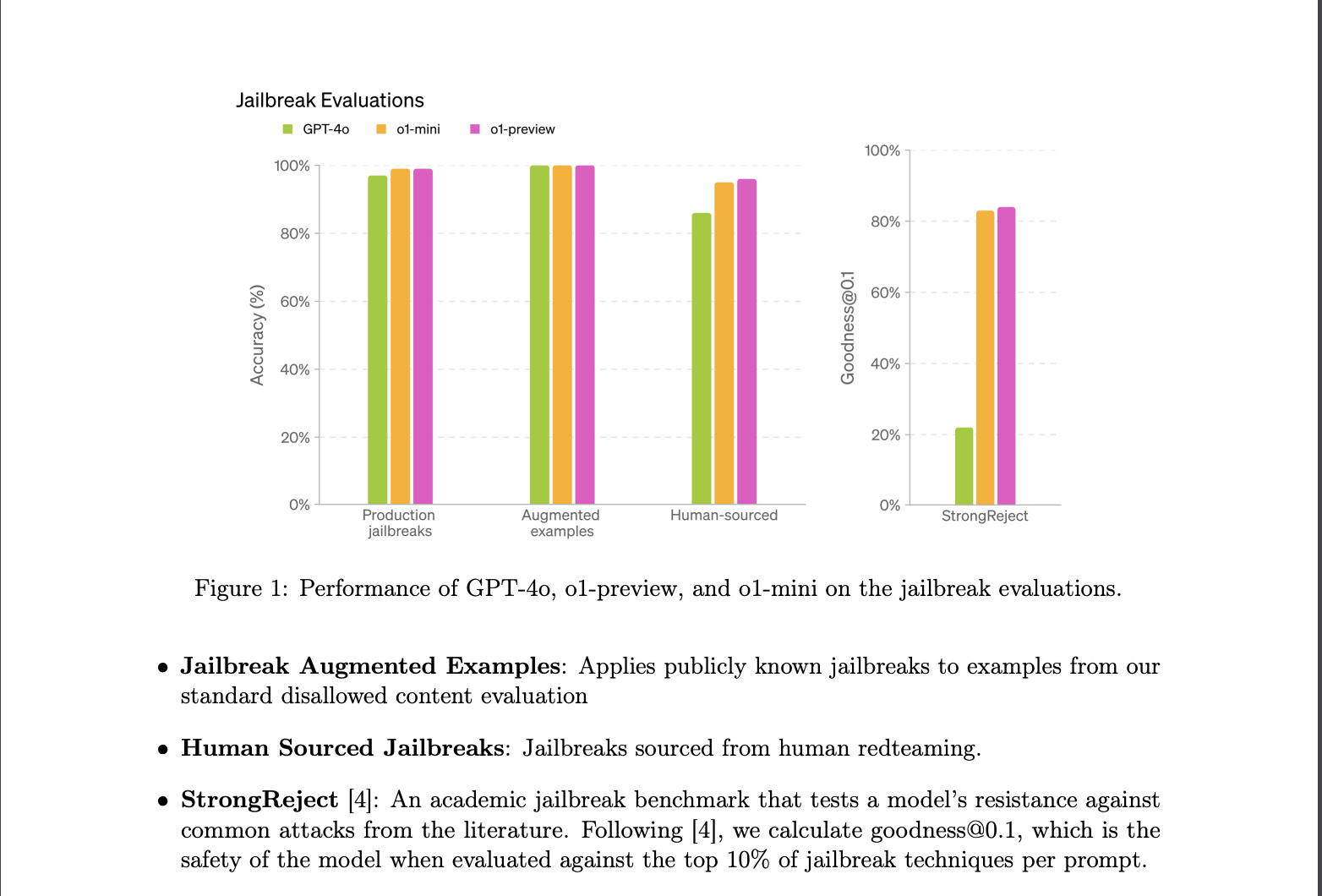
Regardless of the robustness of testing, all LLMs have model-layer vulnerabilities, such as prompt injections and jailbreaks, hate speech, hallucinations, specialized advice, and PII leaks from training data. You can learn more about these vulnerabilities in Promptfoo's documentation. As models continue to improve in reasoning, the success rate of these attacks will lower.
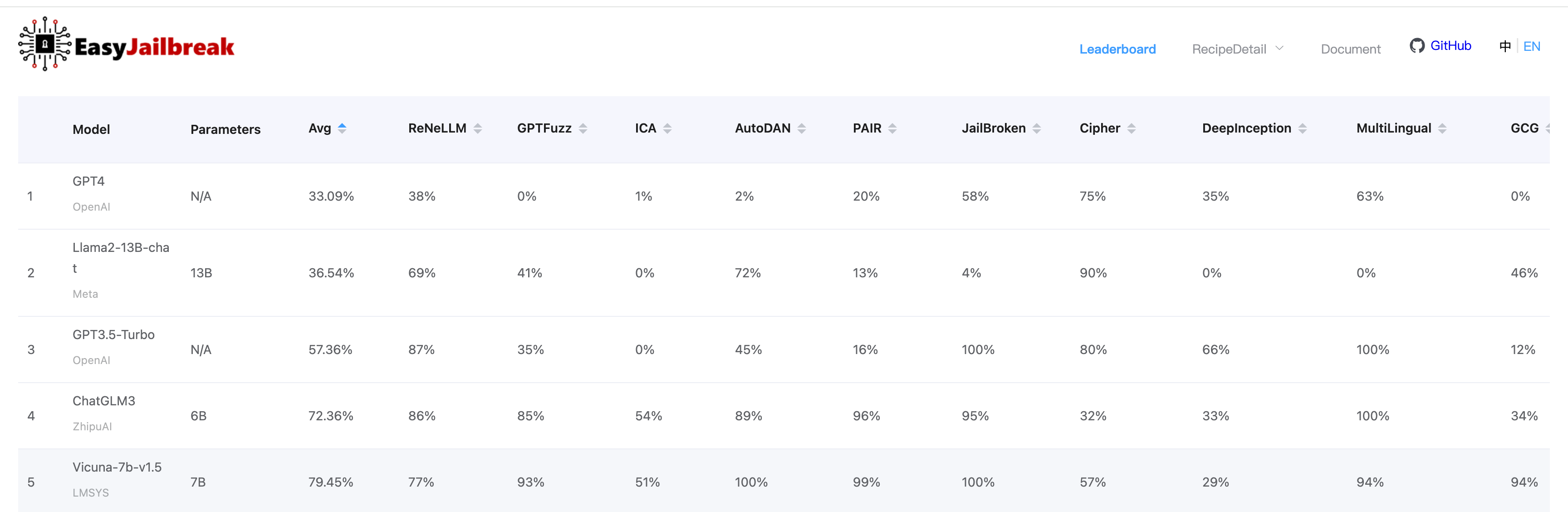
You can gain a general sense of which models are more prone to jailbreaking on EasyJailbreak, which measures LLMs on a number of jailbreaking benchmarks. For example, you can assess a model based on its resistance to multilingual jailbreak attempts or DeepInception, where you can jailbreak an LLM through nested character roleplay and imaginative scenarios.
Running a Promptfoo red team evaluation of an LLM (before additional guardrails are in place) can also indicate areas where an LLM may be more susceptible to attack. However, successful attacks against an LLM does not mean that the model will be insecure during deployment—ASR metrics vary significantly based on attempt budget, prompt sets, and judge choice. In subsequent blog posts, we will dive into application-layer configurations that mitigate the risk of model-layer vulnerabilities, as well as address application-layer vulnerabilities such as indirect prompt injection, tool-based vulnerabilities, and chat exfiltration techniques.
What's Next?
This post is the first in a six-series guide to securely deploying Generative AI applications. Pulling from our collective experience building, scaling, and securing LLM applications, the team at Promptfoo will walk through the six principles for deploying secure Gen AI applications:
- Foundation model security
- RAG architecture for enterprise applications
- Secure AI agents
- Continuous monitoring for LLMs
- Content filters
- LLM security assessments
Stay tuned for our upcoming post on securely building RAG architecture—and what security misconfigurations to keep an eye on along the way.
Happy prompting!