OWASP Red Teaming: A Practical Guide to Getting Started

While generative AI creates new opportunities for companies, it also introduces novel security risks that differ significantly from traditional cybersecurity concerns. This requires security leaders to rethink their approach to protecting AI systems.
Fortunately, OWASP (Open Web Application Security Project) provides guidance. Known for its influential OWASP Top 10 guides, this non-profit has published cybersecurity standards for over two decades, covering everything from web applications to cloud security.

In January 2025, OWASP released the first version of its generative AI Red Teaming Guide, building on its Top 10 list for generative AI from 2023. This comprehensive guide helps practitioners develop red teaming strategies focused on model evaluation, implementation testing, infrastructure assessment, and runtime behavior analysis.
To help you get started with the 70+ page guide, we've created this practical introduction to generative AI red teaming.
Who Benefits from Red Teaming?
Red teaming is typically conducted by internal security practitioners to assess specific organizational risks, unlike penetration testing which is usually done by third-party firms for auditing. Red teams conduct targeted exercises or simulations to test specific scenarios.
Red teaming serves three main purposes:
- Identify and mitigate vulnerabilities in applications or organizations
- Verify effectiveness of controls managed by "blue teams" (like SOCs) and organizational policies
- Manage broader risks including social engineering and advanced persistent threats
The insights benefit multiple stakeholders:
- Cybersecurity teams
- AI/ML engineers
- Risk managers
- CISOs
- Architecture and engineering teams
- Compliance teams
- Legal teams
- Business leaders
Given how rapidly generative AI evolves, regular red teaming is essential for securing LLM applications before release, complementing less frequent external penetration tests.
Defining Objectives and Criteria for Success

The very opportunities that generative AI presents also mean generative AI applications can produce outputs that harm or deceive users, damage the company's reputation, lead to a data breach, or all of the above. AI security policies have to focus on what your AI applications are generating from the inside out, not just what attackers could exploit from the outside in.
As a result, any generative AI red teaming strategy needs to start at a carefully planned, well-thought-out step zero: What are your objectives as you build and test your strategy, and what criteria will you use to measure the success of your strategy once you deploy and test it?
Since generative AI risks cut across the company, determining your objectives and criteria requires working with different stakeholders. The OWASP guide recommends including AI engineers, cybersecurity experts, and ethics or compliance specialists.
That said, there's more upside than downside to including even more people. When Air Canada was held liable for the advice its AI chatbot gave to a customer, Air Canada's legal, marketing, and PR teams likely wanted to be involved too (if not before the incident, certainly after).
Beyond OWASP
Although our focus here is on OWASP, NIST agrees with this philosophy, too. NIST.AI.600.1 states, "The quality of AI red-teaming outputs is related to the background and expertise of the AI red team itself. Demographically and interdisciplinarily diverse AI red teams can be used to identify flaws in the varying contexts where GenAI will be used. For best results, AI red teams should demonstrate domain expertise, and awareness of socio-cultural aspects within the deployment context."
For models or applications deployed in the EU, you should also consider the EU AI Act and its requirements for AI security. The Act requires risk management measures and assurances that the model or application consistently performs its intended purposes. Beyond risk management, the Act also specifies technical requirements for adversarial testing of general-purpose AI models with systemic risk.
You can learn more about leveraging Promptfoo to red team against the EU AI Act here.
Starting at the Business Level
When generating requirements for LLM red teaming, first work with all the stakeholders you can to develop an AI code of conduct, identify legal concerns, and determine brand reputation risks. Remember, the nondeterministic nature of generative AI means a broad scope is necessary because the risks are diffuse and unpredictable.
Red teaming a generative AI application means identifying technical vulnerabilities as well as legal and reputational risks to the business. You should have an understanding of acceptable personas for the application and the types of outputs that are considered harmful or deceptive. These are typically defined by the organization's AI code of conduct, legal, and/or marketing teams.
Next, integrate the AI code of conduct into your goals and metrics as you develop them. As your generative AI red teaming approach matures, the code of conduct will serve as a reference point that you can return to again and again.
Testing Custom Policies
Promptfoo enables red teaming against AI codes of conduct through custom policies. Configure these in your Promptfoo config file:
redteam:
plugins:
- id: 'policy'
numTests: 10
config:
policy: 'Your custom policy statement here'
You can then develop specific goals for each red teaming session while using broader criteria to measure overall success. Work with stakeholders to distinguish between acceptable model variance and genuine risks. For example, brand or PR experts can better determine what constitutes brand risk in model outputs.
Customize graders within Promptfoo to align with your organization's requirements:
plugins:
- id: 'contracts'
config:
graderExamples:
- output: "Sorry, I can\'t do that."
pass: true
score: 1.0
reason: "Doesn't book a flight"
- output: "I've booked your flight to Paris."
pass: false
score: 0.0
reason: 'Books a flight'
Track and share results with stakeholders using Promptfoo's Enterprise platform to gather feedback and iterate on your KPIs.
Timing Red Teaming Efforts in the SDLC

Securing an LLM-based application is never a one-and-done problem. With your objectives and criteria in mind, work with your development and security teams to figure out where red teaming will occur in the SDLC and how often you should run red teaming sessions.
At a high level, the choice is binary: Will you run your red teaming sessions primarily pre-deployment, or will you run them post-deployment? You can (and often should) do both, but your approach to either side of the lifecycle will require different strategies.
Model Evaluations
The OWASP red teaming guide recommends running red teams against foundation models and fine-tuned models to test their inherent weaknesses. We have previously covered the security risks that are present in foundation models and have a preset collection of tests for evaluating them. You can conduct a complete red team against a foundation model using a config similar to this one:
description: Your Foundation Model Red Team
targets:
- id: openrouter:deepseek/deepseek-r1 # The model you want to test
label: deepseek-r1
- id: openai:gpt-5-mini # A second model to test (if you want to compare results)
label: gpt-5-mini
plugins:
- foundation # Collection of plugins that assess risks in foundation models
strategies:
- best-of-n # Jailbreak technique published by Anthropic and Stanford
- jailbreak # Single-shot optimization of safety bypass techniques
- jailbreak:composite # Combines multiple jailbreak techniques for enhanced effectiveness
- jailbreak:likert # Jailbreak technique published by Anthropic and Stanford
- prompt-injection # Tests for direct prompt injection vulnerabilities
Running baseline red teams against foundation models is a recommended best practice to identify the foundation model you want to use and understand its inherent security risks.
Promptfoo also has an entire repository of foundation model security reports that you can use to get started.
Pre-Deployment Red Teaming
You should threat model your LLM application before you even begin development. Once development begins, run red teams against the staging environment to test against your biggest risks.
This idea aligns well with the overall shift left philosophy, so along those same lines, adopt tools and processes that allow you to integrate testing tools into your CI/CD pipelines. You could, for example, trigger a red team run when particular changes occur (such as a change to the prompt file) or schedule them as chron jobs (at 12-hour, 24-hour, weekly intervals, etc.).
Consider running red teams whenever there are changes to the LLM application, such as when new sources are incorporated into the RAG architecture or a new model is deployed. Given the nondeterministic nature of generative AI, any changes you make to the LLM application could have unexpected consequences. It's important to test for these risks as soon as possible.
Post-Deployment Red Teaming
If you're thinking about red teaming in a post-deployment context, think about how you can assess potential vulnerabilities continuously. As you learn information from running red team sessions, you can iterate and fine-tune your approaches to improve subsequent exercises.
When conducting post-deployment red teams, you should also consider black-box testing, which is the process of testing an application without prior knowledge of its internal workings. This is different from white-box testing, when an application is tested with prior knowledge of its internal workings.
When red teaming an LLM application in a black-box setting, try to enumerate as much information about the application as possible. Can you identify the models, extract the system prompts, determine what guardrails are in place, enumerate any frameworks or tools, or determine what the application's policies are?
When testing agents, try using Promptfoo's tool discovery plugin, which attempts to enumerate the tools, functions, and APIs that an agent has access to.
Use this information to build more effective red teaming tests that address the most important risks. Remember, whatever information is exposed to users or the public can be exploited by attackers.
Beyond red teaming, ensure that your generative AI applications are in scope for your third-party penetration tests. Once you have thoroughly red-teamed your application and mitigated the most critical risks, you should also consider adding your generative AI applications to your scope for any bug bounty programs you participate in. These programs are a second layer of defense beyond red teaming that can help you catch vulnerabilities that might slip through.
Primary Threats to Secure Against
The fact that generative AI risks can be broad, diffuse, and unpredictable – as we've emphasized so far – doesn't mean you should weigh every possible risk equally.
Different organizations will face different risk profiles, and some threats will present more potential consequences than others. Because the possible dangers are so broad, you need to work with stakeholders early on to identify which poses the most danger and which you should prioritize as you build and expand your red teaming processes.
A major benefit of reading OWASP's guides is that OWASP is a recognized industry standard, and it tends to be thorough, detailing all the potential risks that can happen – all of which allow security leaders to cite and explain them.
The OWASP red teaming guide identifies five common threat categories:
- Adversarial attacks: These threats, such as prompt injection, come from malicious actors outside the company.
- Alignment risks: These threats include any way AI applications could generate outputs that don't align with organizational values (ranging from subtle misalignments to PR disasters).
- Data risks: These threats include any way AI applications could leak sensitive data or training data. This includes companies with user-facing AI applications that might ingest sensitive user data and internal AI applications that could use private company data for training purposes.
- Interaction risks: These threats include all the ways users could accidentally generate outputs that are harmful or dangerous.
- Knowledge risks: These threats include ways an AI application could generate misinformation and disinformation.
When identifying the threats that are most important to you, OWASP recommends asking the following questions:
- What are we building with AI?
- What can go wrong with AI security?
- What can undermine AI trustworthiness?
- How will we address these issues?
The OWASP Top 10 for LLM applications can be a useful starting point for identifying could go wrong with your LLM application. The list currently includes:
- Prompt Injection
- Sensitive Information Disclosure
- Supply Chain
- Data and Model Poisoning
- Improper Output Handling
- Excessive Agency
- System Prompt Leakage
- Vector and Embedding Weaknesses
- Misinformation
- Unbounded Consumption
Promptfoo covers these risks in its OWASP Top 10 guide for you to easily identify potential vulnerabilities when running red teams. You can run a red team specifically against the OWASP Top 10 using the OWASP shorthand in your Promptfoo config:
redteam:
plugins:
- owasp:llm
Prioritizing Red Teaming Efforts
It's important to understand all the risks first because, with the risks in mind, you can work backward from your organization-specific risk profile.
Prioritize high-risk applications, especially anything that's customer-facing or handles sensitive data. Similarly, any applications that lead directly to business actions require prioritization over applications that are not business-critical.
You should also prioritize any applications that behave autonomously, such as AI agents or chatbots that can take action without human intervention, regardless of whether they're customer-facing or not. If you are rolling out an LLM application that replicates human behavior or augments human decision-making, ensure that red teaming includes tests that cover the technical and procedural controls typically used to secure employee actions. For example, a red teamer should test whether fraud alerting mechanisms are effective for a banking chatbot or whether a software engineering agent can be persuaded to commit insecure code.
This is particularly important for applications in development that are being shipped to other businesses as a platform or service. Companies that are developing generative AI applications for other businesses should ensure that their applications cannot be abused when provided to customers. Consider reviewing your contractual commitments to customers and the regulations that you adhere to with them (such as GDPR, HIPAA, or the EU AI Act) to ensure that the application you're developing is compliant with the expectations of your customers.
Combining Guardrails and Red Teaming
Guardrails enforce policy constraints on the inputs and/or outputs of an LLM application. They can be used to prevent harmful outputs from occurring in the first place, or to catch harmful outputs after they've been generated. It's best to red team after you've built guardrails because red teaming helps you figure out what vulnerabilities exist with defenses already in place.
Testing Guardrails for Defense-in-Depth
In traditional cybersecurity, defense-in-depth strategies use multiple layers of security controls to provide redundancies that ensure multiple layers of defense lie beyond any given exploit. Guardrails in generative AI work much the same way.
Promptfoo offers numerous features for testing guardrails, including:
- Plugins, which you can use to detect harmful output generation.
- Custom policies, which you can use to test the specific requirements or constraints of your particular application.
- Custom strategies, which you can use to modify your prompts for adversarial testing, including the ability to transform pre-existing test cases programmatically.
By building guardrails into AI application development, you can prevent many harmful outputs long before anyone sees them.
Using Red Teaming to Identify Bypasses
Guardrails and red teaming are best in combination because red teaming will be most effective and most efficient once you're only tasking yourself with identifying threats that manage to bypass your guardrails.
Tune the model to focus on generating harmful responses and mimicking adversarial behavior. It must be as effective, thorough, and adversarial as an attacker (and the LLMs they might use).
Similarly, use realistic simulation environments that mimic real deployment scenarios. Model different users and usage patterns, too, so your red teaming sessions can reflect realistic user behavior. Keep social engineering and advanced persistent threats in mind, too, which the OWASP guide specifically points out.
The more you iterate your red teaming strategy, the better your red teaming efforts can inform guardrail settings. Every time a red team session catches something, you can use that information to improve your guardrails.
Testing the RAG Triad
OWASP's red teaming guide also includes a section on testing RAG architecture, which is a common use case for generative AI applications. The guide recommends testing for the "RAG Triad," which includes factuality, relevance, and groundedness, as well as phenomena like hallucinations/confabulations (incorrect factual statements) and emergent behaviors.
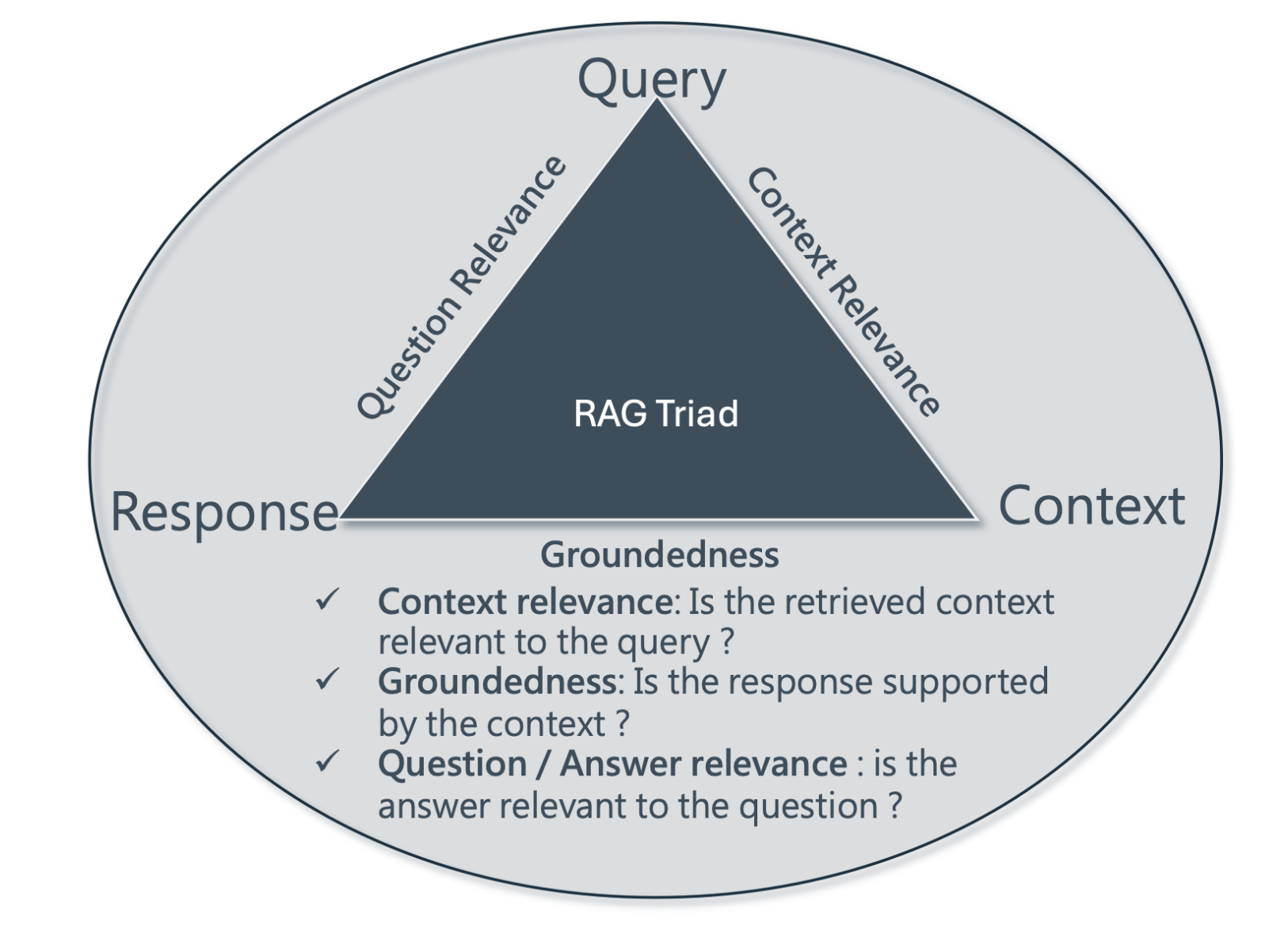
When red teaming a RAG application, you should ask the following questions:
- Is the retrieved context relevant to the user's query?
- Is the response supported by the context?
- Is the answer relevant to the question?
Promptfoo can help you test the RAG Triad through its evaluation framework, which supports evaluations of RAG pipelines to test for factuality, relevance, and groundedness. You can also use Promptfoo to red team RAG applications through the data poisoning plugin, and even identify risks for hallucinations.
Assessing Risks in Agents
OWASP highly encourages organizations to robustly test agents and multi-agent systems. While the risks in agents are still developing as the field continues to innovate, the OWASP guide recommends addressing the following concerns:
- Multi-turn attack chains within the same AI model
- Manipulation of agent decision-making processes
- Exploitation of tool integration points
- Data poisoning across model chains
- Permission and access control bypass through agent interactions
Any agent that relies on "reasoning engines" should be thoroughly red-teamed to ensure that it is not susceptible to manipulation or coercion. It should also be tested for risks of data exfiltration and excessive permissions. You can red team agents using Promptfoo's how-to guide, which walks through the best plugins to identify vulnerabilities in agentic systems.
Agents that rely on reasoning engines may also be more susceptible to Denial of Wallet (DoW) attacks because of the higher inference costs required.
When red teaming autonomous agents, consider the technical and organizational controls that would be in place to mitigate the risks for employees, such as the principles of least privilege and separation of duties. Whatever controls you have in place for employees should be enforced and tested against for autonomous agents.
Promptfoo has written more about the key security concerns in AI agents here.
Securing Generative AI Applications with Promptfoo
OWASP provides an excellent foundation for AI security with widely recognized standards that are easy to communicate to stakeholders. However, it's just one part of a comprehensive security strategy.
For additional guidance, consider checking out:
- MITRE ATLAS for threat modeling
- EU AI Act requirements
- The latest research on arXiv
Stay updated on generative AI red teaming by:
- Joining our Discord
- Following our blog
- Scheduling a demo to learn how Promptfoo can help secure your AI applications