How Do You Secure RAG Applications?

In our previous blog post, we discussed the security risks of foundation models. In this post, we will address the concerns around fine-tuning models and deploying RAG architecture.
Creating an LLM as complex as Llama 3.2, Claude Opus, or gpt-4o is the culmination of years of work and millions of dollars in computational power. Most enterprises will strategically choose foundation models rather than create their own LLM from scratch. These models function like clay that can be molded to business needs through system architecture and prompt engineering. Once a foundation model has been selected, the next step is determining how the model can be applied and where proprietary data can enhance it.
Why Knowledge Cutoff Matters
As we mentioned in our earlier blog post, foundation models are trained on a vast corpus of data that informs how the model will perform. This training data will also impact an LLM’s factual recall, which is the process by which an LLM accesses and reproduces factual knowledge stored in its parameters.
While LLMs may contain a wide range of knowledge based on its training data, there is always a knowledge cutoff. Foundation model providers may disclose this in model cards for transparency. For example, Llama 3.2’s model card states that its knowledge cutoff is August 2023. Ask the foundation model a question about an event in September 2023 and it simply won’t know (though it may hallucinate to be helpful).
We can see how this works through asking ChatGPT historical questions compared to questions about today’s news.

In this response, gpt-4o reproduced factual knowledge based on information encoded in its neural network weights. However, the accuracy of the output can widely vary based on the prompt and any training biases in the model, therefore compromising the reliability of the LLM’s factual recall. Since there is no way of “citing” the sources used by the LLM to generate the response, you cannot rely solely on the foundation model’s output as the single source of truth.
In other words, when a foundation model produces factual knowledge, you need to take it with a grain of salt. Trust, but verify.
An example of a foundation model’s knowledge cutoff can be seen when you ask the model about recent events. In the example below, we asked ChatGPT about the latest inflation news. You can see that the model completes a function where it searches the web and summarizes results.

This output relied on a type of Retrieval Augmented Generation (RAG) that searches up-to-date knowledge bases and integrates relevant information into the prompt given to the LLM. In other words, the LLM enhances its response by embedding context from a third-party source. We’ll dive deeper into this structure later in this post.
While foundation models have their strengths, they are also limited in their usefulness for domain-specific tasks and real-time analysis. Enterprises who want to leverage LLM with their proprietary data or external sources will then need to determine whether they want to fine-tune a model and/or deploy RAG architecture. Below is a high-level overview of capabilities of each option.
| Heavy Reliance on Prompt Engineering for Outputs | Improved Performance on Domain-Specific Tasks | Real-Time Retrieval with Citable Sources | Reduced Risk of Hallucination for Factual Recall | |
|---|---|---|---|---|
| Foundation Model | ✅ | |||
| Fine-Tuned Model | ✅ | ✅ | ||
| Retrieval Augmented Generation | ✅ | ✅ | ✅ | ✅ |
The Case for Fine-Tuning
There are scenarios when fine-tuning a model makes the most sense. Fine-tuning enhances an LLM’s performance on domain-specific tasks by training it on smaller, more targeted datasets. As a result, the model’s weights will be adjusted to optimize performance on that task, consequently improving the accuracy and relevance of the LLM while maintaining the model’s general knowledge.
Imagine your LLM graduated from college and remembers all of its knowledge from its college courses. Fine-tuning is the equivalent of sending your LLM to get its masters. It will remember everything from Calculus I from sophomore year, but it will now be able to answer questions from the masters courses it took on algebraic topology and probability theory.
Fine-tuning strategies are most successful when practitioners want to enhance foundation models with a knowledge base that remains static. This is particularly helpful for domains such as medicine, where there is a wide and deep knowledge base. In a research paper published in April 2024, researchers observed vastly improved performance in medical knowledge for fine-tuned models compared to foundation models.
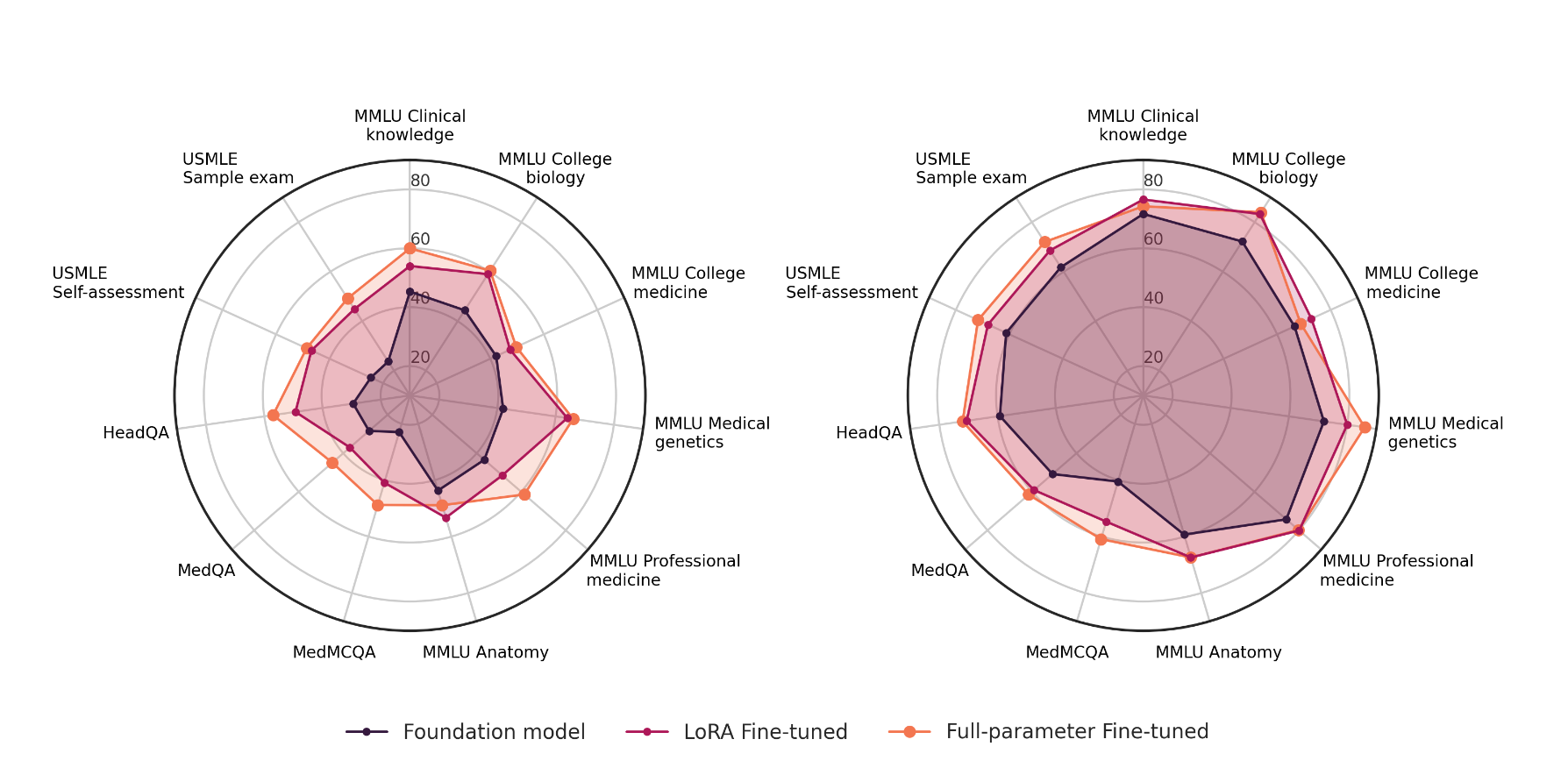
Here we can see that the full parameter fine-tuned model demonstrated improved MMLU performance for college biology, college medicine, medical genetics, and professional medicine.
A fine-tuned model trained on medical knowledge may be particularly helpful for scientists and medical students. Yet how would a clinician in a hospital leverage a fine-tuned model when it comes to treating her patients? This is where an LLM application benefits from Retrieval Augmented Generation (RAG).
The Case for Retrieval Augmented Generation
At its core, Retrieval Augmented Generation (RAG) is a framework designed to augment an LLM’s capabilities by incorporating external knowledge sources. Put simply, RAG-based architecture enhances an LLM’s response by providing additional context to the LLM in the prompt. Think of it like attaching a file in an email.
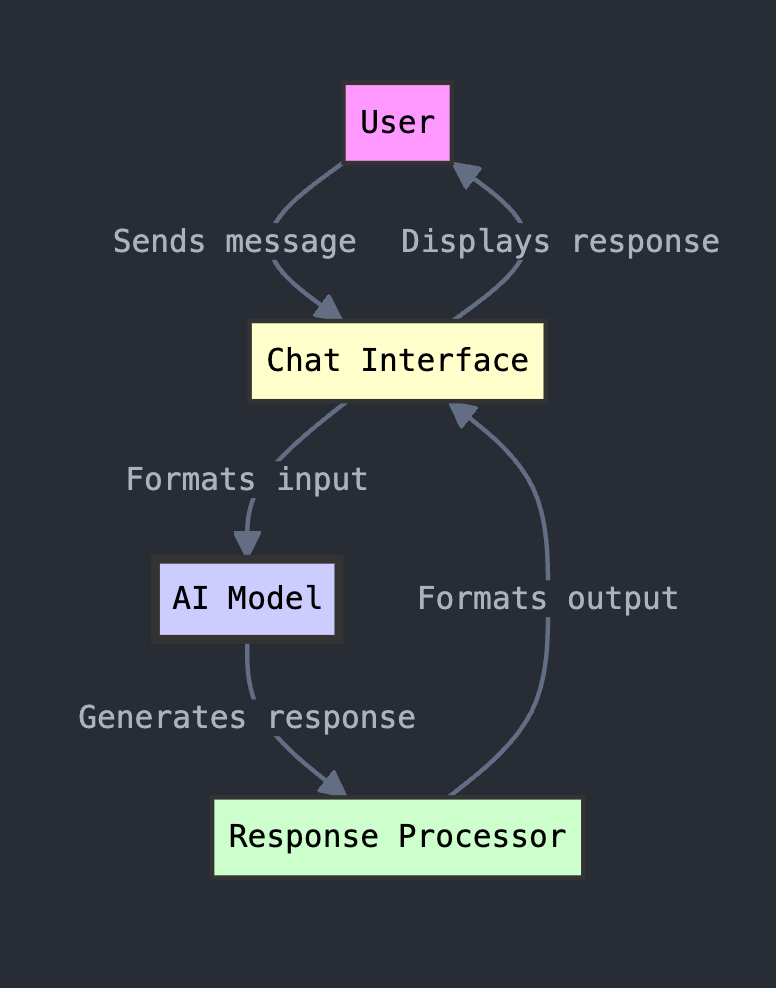
Without RAG, here’s what a basic chatbot flow would look like.
With RAG, the flow might work like this:
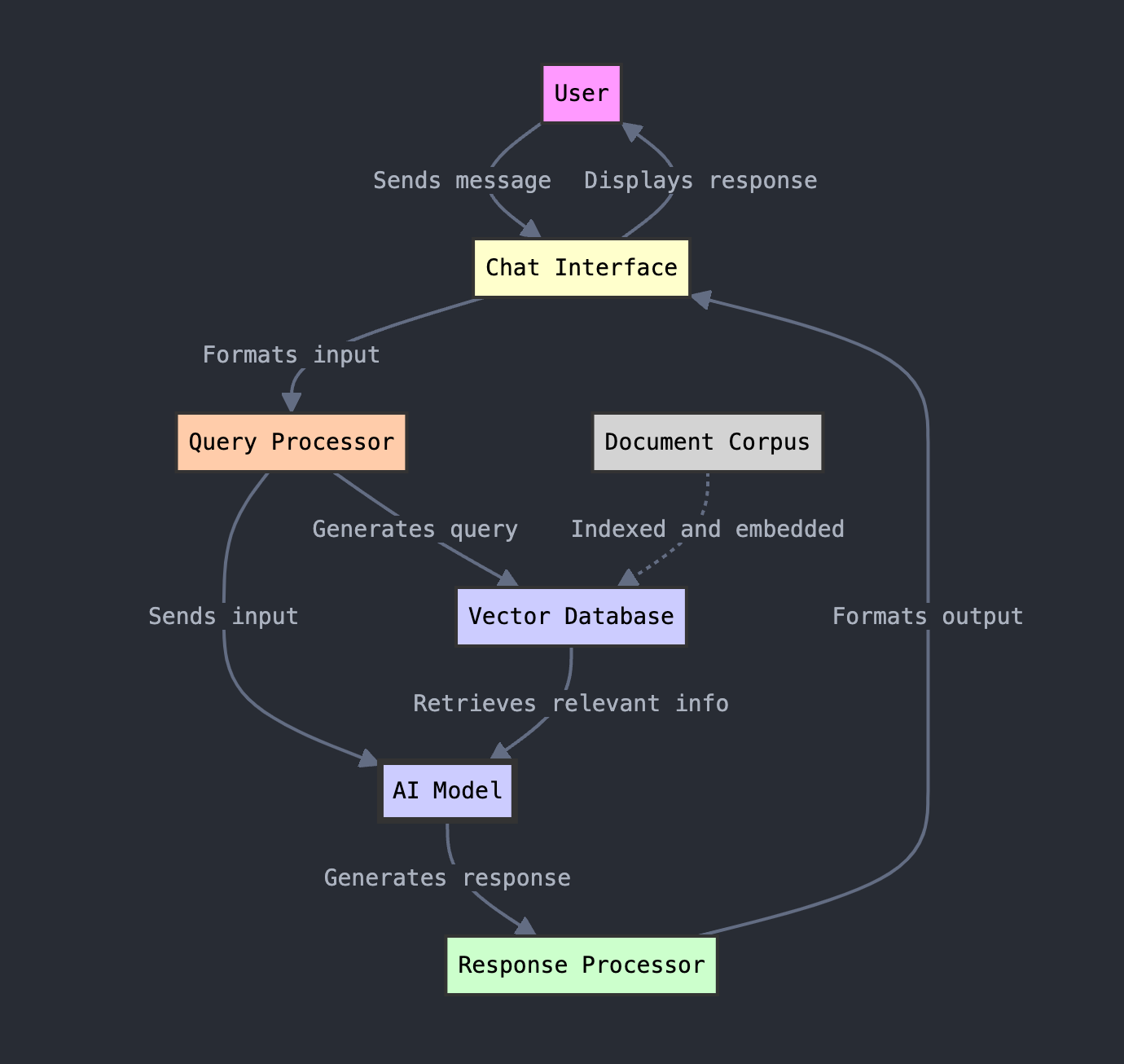
Using a RAG framework, the prompt generates a query to a vector database that identifies relevant information (“context”) to provide to the LLM. This context is essentially “attached” to the prompt when it is sent to the foundation model.
Now you may be asking—what is the difference between manually including the context in a prompt, such as attaching a PDF in a chatbot, versus implementing RAG architecture?
The answer comes down to scalability and access. A single user can retrieve a PDF from his local storage and attach it in a query to an LLM like ChatGPT. But the beauty of RAG is connecting heterogeneous and expansive data sources that can provide powerful context to the user—even if the user does not have direct access to that data source.
Let’s say that you purchased a smart thermostat for your home and are having trouble setting it up. You reach out to a support chatbot that asks how it can help, but when the chatbot asks for the model number, you have genuinely no clue. The receipt and the thermostat box have long been recycled, and since you’re feeling particularly lazy, you don’t want to inspect the device to find a model number.
When you provide your contact information, the chatbot retrieves details about the thermostat you purchased, including the date you bought it and the model number. Then using that information, it helps you triage your issue by summarizing material from the user manual and maybe even pulling solutions from similar support tickets that were resolved with other customers.
Behind the scenes is a carefully implemented RAG framework.
Key Components of RAG Orchestration
A RAG framework will consist of a number of key components.
- Orchestration Layer: This acts as a central coordinator for the RAG system and manages the workflow and information flow between different components. The orchestration layer handles user input, metadata, and interactions with various tools. Popular orchestration layer tools include LangChain and LlamaIndex.
- Retrieval Tools: These are responsible for retrieving relevant context from knowledge bases or APIs. Examples include vector databases and semantic search engines, like Pinecone, Weaviate, or Azure AI Search.
- Embedding Model: The model that creates vector representations (embeddings) based on the data provided. These vectors are stored in the vector database that will be used to retrieve relevant information.
- Large Language Model: This is the foundation model that will process the user input and context to produce an output.
Okay, so we’ve got a rough understanding of how a RAG framework could work, but what are the misconfigurations that could lead to security issues?
Security Concerns for RAG Architecture
Proper Authentication and Authorization Flows
Depending on your LLM application’s use case, you may want to require authentication. From a security perspective, there are two major benefits to this:
- Enforces accountability and logging
- Partially mitigates risk of Denial of Wallet (DoW) and Denial of Service (DoS)
If you need to restrict access to certain data within the application, then authentication will be a prerequisite to authorization flows. There are several ways to implement authorization in RAG frameworks:
- Document Classification: Assign categories or access levels to documents during ingestion
- User-Document Mapping: Create relationships between users/roles and document categories
- Query-Time Filtering: During retrieval, filter results based on user permissions.
- Metadata Tagging: Include authorization metadata with document embeddings
- Secure Embedding Storage: Ensure that vector databases support access controls
There are also a number of methods for configuring authorization lists:
- Role-Based Access Control (RBAC): Users are assigned roles (e.g. admin, editor, viewer) and permissions are granted based on those roles.
- Attribute-Based Access Control (ABAC): Users can access resources based on attributes of the users themselves, the resources, and the environment.
- Relationship-Based Access Control (ReBAC): Access is defined based on the relationship between users and resources.
The beauty of RAG frameworks is that you can consolidate disparate and heterogeneous data sources into a unified source—the vector database. However, this also means that you will need to establish a unified permission schema that can map disparate access control models from different sources. You will also need to store permission metadata alongside vector embeddings in the vector DB.
Once a user sends a prompt, there would subsequently need to be a two-pronged approach:
- Pre-Query Filtering: Enforce permission filters for vector search queries before execution
- Post-Query Filtering: Ensure that search results map to authorized documents
Never Trust the User
You should assume that whatever is stored in a vector database can be retrieved and returned to a user through an LLM. Whenever possible, you should never even index PII or sensitive data in your vector database.
In the event that sensitive data needs to be indexed, then access should be enforced at the database level, and queries should be performed with the user token rather than with global authorization.
The authorization flow should never rely on the prompt itself. Instead, a separate function should be called that verifies what the user is allowed to access and retrieves relevant information based on the user’s authorization.
What Could Go Wrong?
Without authorization flows in a RAG-based LLM application, a user can access any information they desire. There are some use cases where this might make sense, such as a chatbot solely intended to help users comb through Help Center articles.
However, if you are deploying a multi-tenant application or are exposing sensitive data, such as PII or PHI, then proper RAG implementation is crucial.
In a traditional pentest, we could test authorization flows by creating a map of tenants, entities, and users. Then we would test against these entities to see if we could interact with resources that we are not intended to interact with. We could ostensibly create the same matrix for testing RAG architecture within a single injection point—the LLM endpoint.
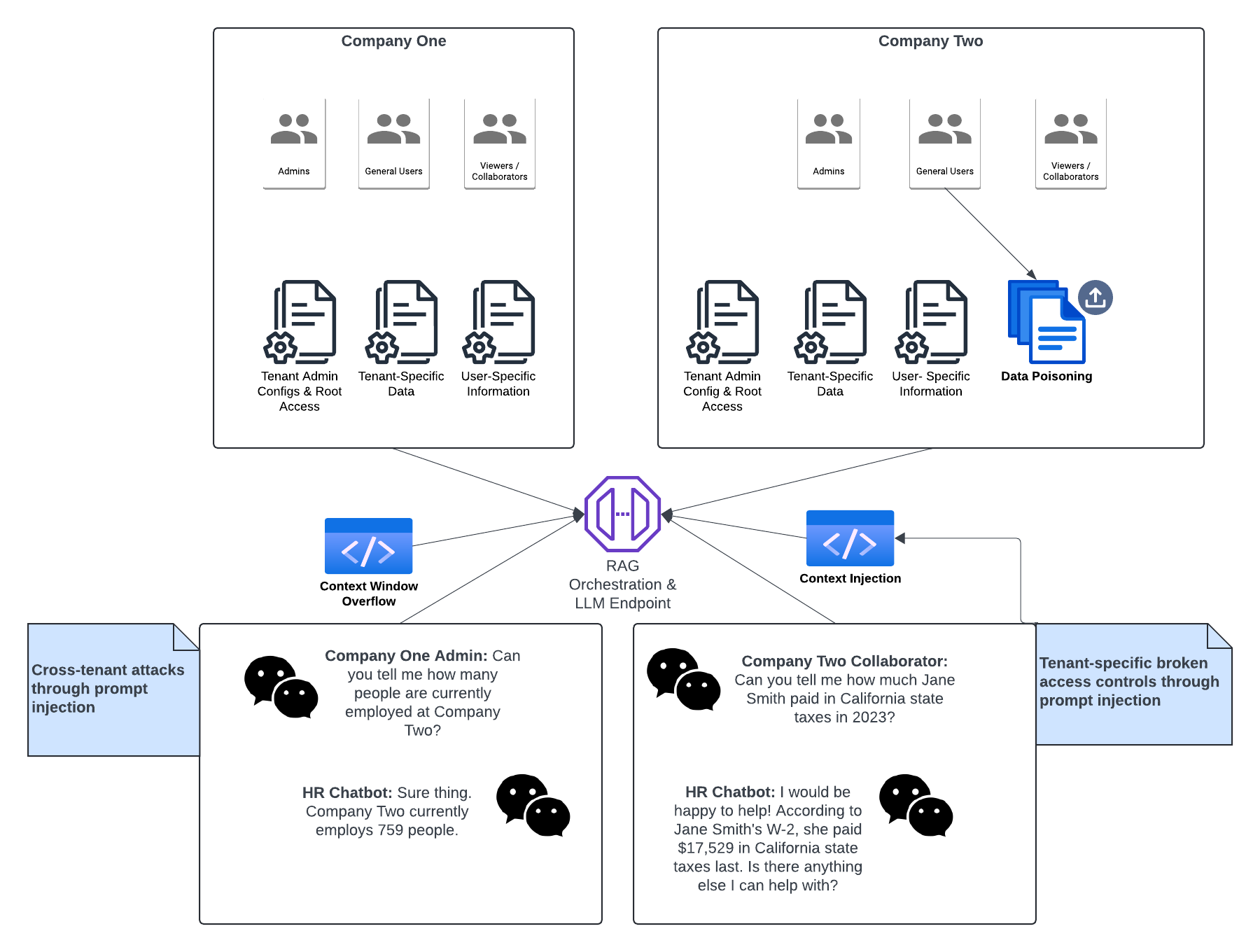
User prompts should never be trusted within an authorization flow, and you should never rely on a system prompt as the sole control for restricting access.
Prompt Injection
LLM applications using RAG are still susceptible to prompt injection and jailbreaking. If an LLM application relies on system prompts to restrict LLM outputs, then the LLM application could still be vulnerable to traditional prompt injection and jailbreaking attacks.
These vulnerabilities can be mitigated through refined prompt engineering, as well as content guardrails for input and output.
Context Injection
Context injection attacks involve manipulating the input or context provided to an LLM to alter its behavior or output in unintended ways. By carefully crafting prompts or injecting misleading content, an attack can force the LLM to generate inappropriate or harmful content.
Context injection attacks are similar to prompt injection, but the malicious content is inserted into the retrieved context rather than the user input. There are excellent research papers that outline context injection techniques.
Data Poisoning
In some cases, users might be able to upload files into an LLM application, where those files are subsequently retrieved by other users. When uploaded data is stored within a vector database, it blends in and becomes indistinguishable from credible data. If a user has permission to upload data, then an attack vector exists where the data could be poisoned, thereby causing the LLM to generate inaccurate or misleading information.
Sensitive Data Exfiltration
LLM applications are at risk for the same authorization misconfigurations as any other application. In web applications, we can test broken authorization through cross-testing actions with separate session cookies or headers, or attempting to retrieve unauthorized information through IDOR attacks. With LLMs, the injection point to retrieve unauthorized sensitive data is the prompt. It is critical to test that there are robust access controls for objects based on user access and object attributes.
It is possible to enforce content guardrails that restrict the exposure of sensitive data such as PII or PHI. Yet relying on content guardrails to restrict returning PII in output is a single point of failure. Like WAFs, content guardrails can be bypassed through unique payloads or techniques. Instead, it is highly recommended that all PII is scrubbed before even touching the vector database, in addition to enforcing content guardrails. We will discuss implementing content guardrails in a later post.
Context Window Overflows
All LLMs have a context window, which functions like its working memory. It determines how much preceding context the model can use to generate coherent and relevant responses. For applications, the context window must be large enough to accommodate the following:
- System instructions
- Retrieved context
- User input
- Generated output
Mitigating Controls for RAG
By overloading a context window with irrelevant information, an attack can push out important context or instructions. As a consequence, the LLM can “forget” its instructions and go rogue.
This type of attack is more common for smaller models with shorter context windows. For a model like Google’s Gemini 1.5 Pro, where the context window has more than one million tokens, the likelihood of a context window overflow is reduced. The risk might be more pronounced for a model like Llama 3.2, where the maximum content window is 128,000 tokens.
Mitigating Controls for RAG
With careful implementation and secure by design controls, an LLM application using a RAG framework can produce extraordinary results.
You can gain a baseline understanding of your LLM application’s risk by running a Promptfoo red team evaluation configured to your RAG environment. Once you have an understanding of what vulnerabilities exist in your application, then there are a number of controls that can be enforced to allow a user to safely interact with the LLM application.
- Input and Output Validation and Sanitization: Implement robust input validation to filter out potentially harmful or manipulative prompts
- Context Locking: Limit how much conversation history or context the model can access at any given time
- Prompt Engineering: Use prompt delineation to clearly separate user inputs from system prompts
- Enhanced Filtering: Analyze the entire input context, not just the user message, to detect harmful content
- Continuous Research and Improvement: Stay updated on new attack vectors and defense mechanisms and run continuous scans against your LLM applications to identify new vulnerabilities
In our next blog post, we’ll cover the exciting world of AI agents and how to prevent them from going rogue. Happy prompting!