Model Scanning
Overview
ModelAudit is a lightweight static security scanner for machine learning models integrated into Promptfoo. It allows you to quickly scan your AIML models for potential security risks before deploying them in production environments.
By invoking promptfoo scan-model, you can use ModelAudit's static security scanning capabilities.
Purpose
AI/ML models can introduce security risks through:
- Malicious code embedded in pickled models
- Suspicious TensorFlow operations
- Potentially unsafe Keras Lambda layers
- Encoded payloads hidden in model structures
- Risky configurations in model architectures
ModelAudit helps identify these risks before models are deployed to production environments, ensuring a more secure AI pipeline.
Usage
Basic Command Structure
promptfoo scan-model [OPTIONS] PATH...
Examples
# Scan a single model file
promptfoo scan-model model.pkl
# Scan multiple models and directories
promptfoo scan-model model.pkl model2.h5 models_directory
# Export results to JSON
promptfoo scan-model model.pkl --format json --output results.json
# Add custom blacklist patterns
promptfoo scan-model model.pkl --blacklist "unsafe_model" --blacklist "malicious_net"
Options�
| Option | Description |
|---|---|
--blacklist, -b | Additional blacklist patterns to check against model names |
--format, -f | Output format (text or json) [default: text] |
--output, -o | Output file path (prints to stdout if not specified) |
--timeout, -t | Scan timeout in seconds [default: 300] |
--verbose, -v | Enable verbose output |
--max-file-size | Maximum file size to scan in bytes [default: unlimited] |
Supported Model Formats
ModelAudit can scan:
- PyTorch models (
.pt,.pth) - TensorFlow SavedModel format
- Keras models (
.h5,.keras,.hdf5) - Pickle files (
.pkl,.pickle) - Model configuration files (
.json,.yaml, etc.)
Security Checks Performed
The scanner looks for various security issues, including:
- Malicious Code: Detecting potentially dangerous code in pickled models
- Suspicious Operations: Identifying risky TensorFlow operations
- Unsafe Layers: Finding potentially unsafe Keras Lambda layers
- Blacklisted Names: Checking for models with names matching suspicious patterns
- Dangerous Serialization: Detecting unsafe pickle opcodes and patterns
- Encoded Payloads: Looking for suspicious strings that might indicate hidden code
- Risky Configurations: Identifying dangerous settings in model architectures
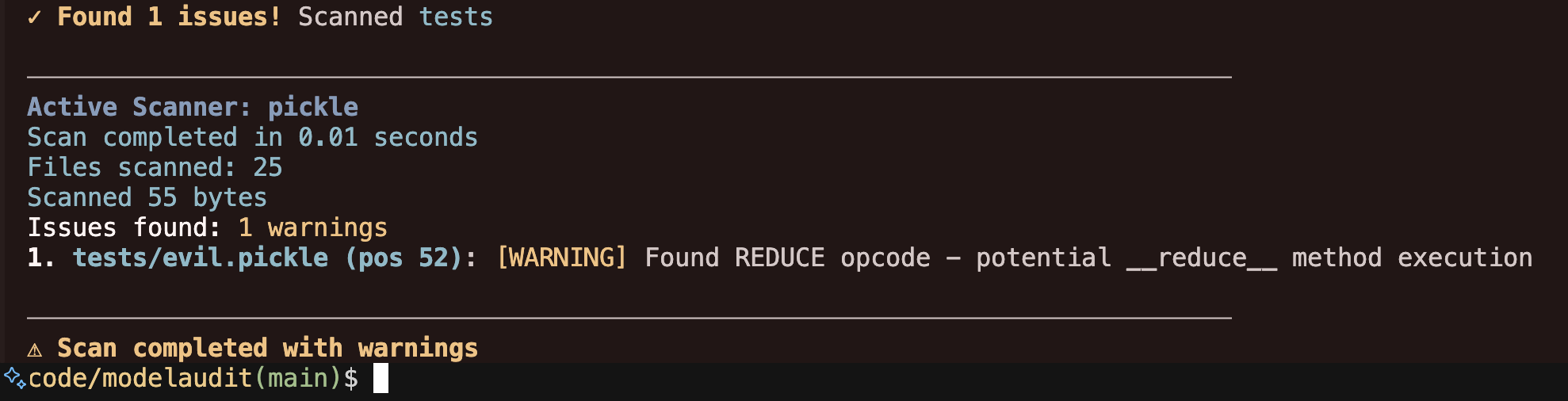
Interpreting Results
The scan results are classified by severity:
- ERROR: Definite security concerns that should be addressed immediately
- WARNING: Potential issues that require review
- INFO: Informational findings, not necessarily security concerns
- DEBUG: Additional details (only shown with
--verbose)
Integration in Workflows
ModelAudit is particularly useful in CI/CD pipelines when incorporated with Promptfoo:
# Example CI/CD script segment
npm install -g promptfoo
promptfoo scan-model --format json --output scan-results.json ./models/
if [ $? -ne 0 ]; then
echo "Security issues found in models! Check scan-results.json"
exit 1
fi
Requirements
ModelAudit is included with Promptfoo, but specific model formats may require additional dependencies:
# For TensorFlow models
pip install tensorflow
# For PyTorch models
pip install torch
# For Keras models with HDF5
pip install h5py
# For YAML configuration scanning
pip install pyyaml