Getting started
This guide will walk you through creating a working eval that tests prompts across multiple models and opens a web view for comparing outputs.
After installing promptfoo, you can set up your first config file in a few ways:
Running an example
Set up your first config file with a pre-built example by running this command with npx, npm, or brew:
- npx
- npm
- brew
npx promptfoo@latest init --example getting-started
npm install -g promptfoo
promptfoo init --example getting-started
brew install promptfoo
promptfoo init --example getting-started
This will create a new directory with a basic example that tests translation prompts across different models. The example includes:
- A configuration file
promptfooconfig.yamlwith sample prompts, providers, and test cases. - A
README.mdfile explaining how the example works.
Most providers need authentication. For OpenAI:
export OPENAI_API_KEY=sk-abc123
Then navigate to the example directory, run the eval, and view results:
- npx
- npm
- brew
cd getting-started
npx promptfoo@latest eval
npx promptfoo@latest view
cd getting-started
promptfoo eval
promptfoo view
cd getting-started
promptfoo eval
promptfoo view
Set up via the CLI
To start from scratch, run promptfoo init to create a config through an interactive CLI walkthrough:
- npx
- npm
- brew
npx promptfoo@latest init
promptfoo init
promptfoo init
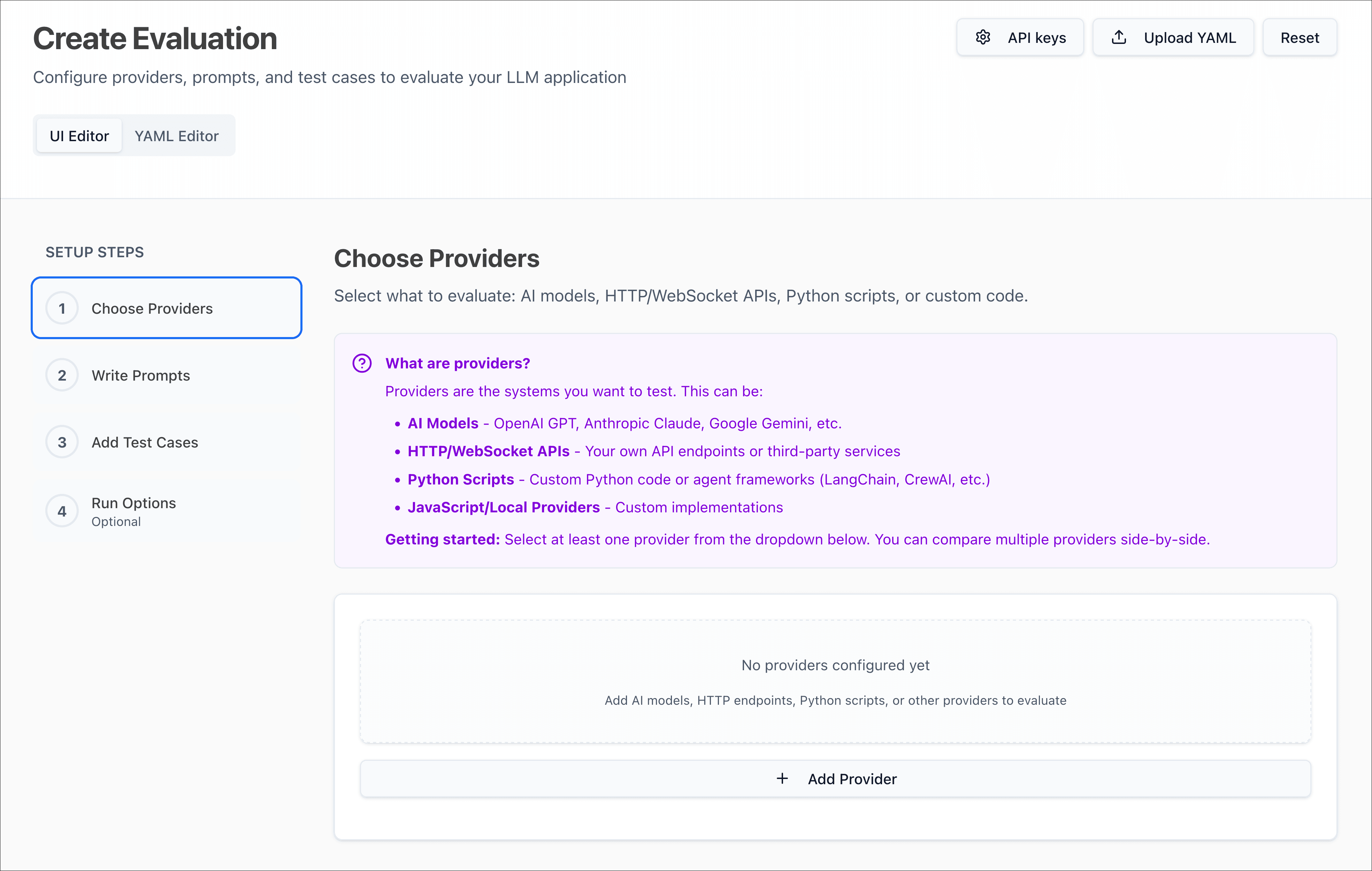
Set up via the Web UI
If you prefer a visual interface, run promptfoo eval setup to configure your first eval through the web UI:
- npx
- npm
- brew
npx promptfoo@latest eval setup
promptfoo eval setup
promptfoo eval setup
This opens a browser-based setup flow that walks you through creating prompts, choosing providers, and adding test cases.
Configuration
Now that you've created an initial configuration, you can update promptfooconfig.yaml with your own prompts, providers, and test cases:
-
Set up your prompts: Open
promptfooconfig.yamland add prompts that you want to test. Use double curly braces for variable placeholders:{{variable_name}}. For example:prompts:- 'Convert the following English text to {{language}}: {{input}}' -
Add providers: Add
providersto specify AI models you want to test. Promptfoo supports 60+ providers including OpenAI, Anthropic, Google, and many others:providers:- openai:chat:gpt-5.4- openai:chat:gpt-5.4-mini- anthropic:messages:claude-opus-4-6- google:gemini-3-pro-preview# Or use your own custom provider- file://path/to/custom/provider.pyThis includes cloud APIs, local models like Ollama, and custom Python or JavaScript code.
-
Add test inputs: Add some example inputs for your prompts. Optionally, add assertions to set output requirements that are checked automatically.
For example:
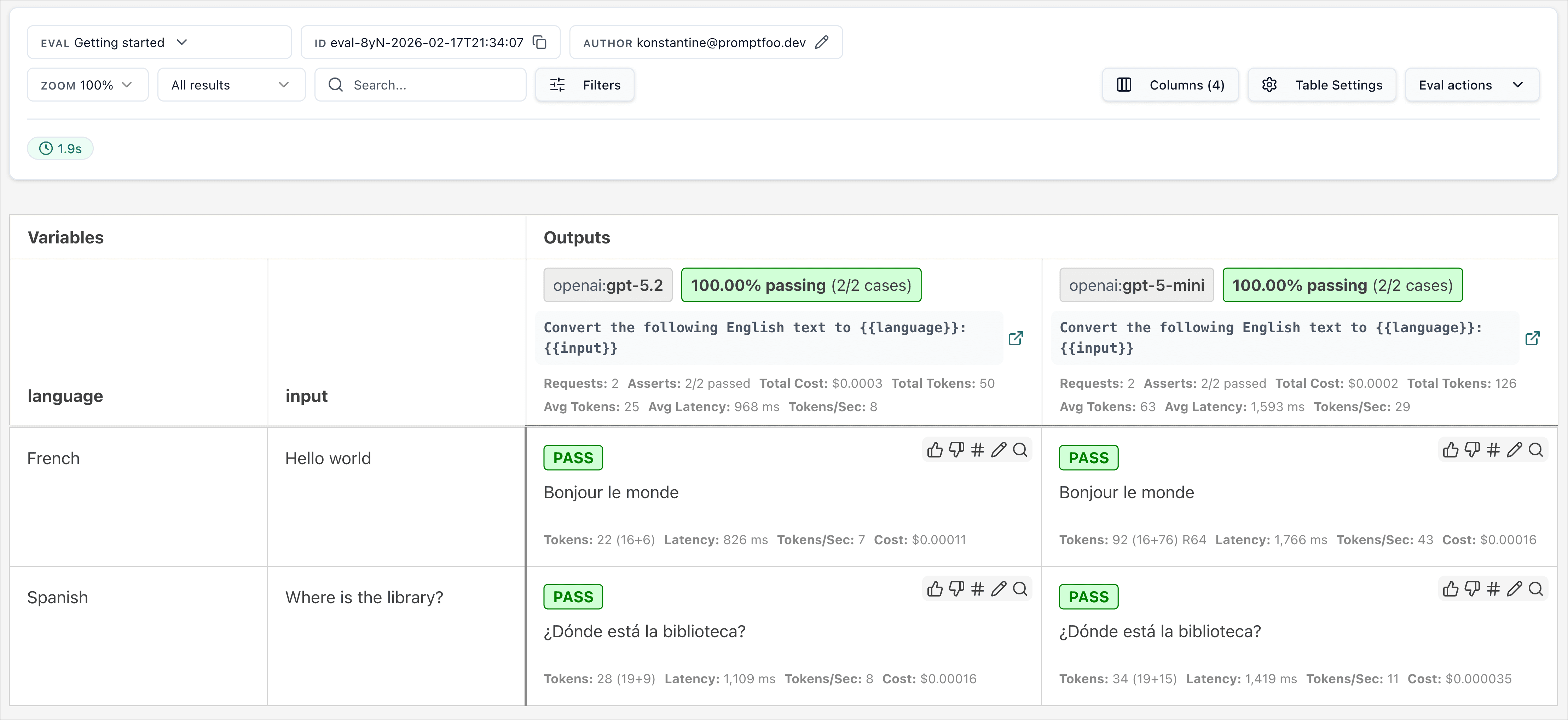
tests:- vars:language: Frenchinput: Hello worldassert:- type: containsvalue: 'Bonjour le monde'- vars:language: Spanishinput: Where is the library?assert:- type: icontainsvalue: 'Dónde está la biblioteca'When writing test cases, think of core use cases and potential failures that you want to make sure your prompts handle correctly.
-
Run the evaluation: Make sure you're in the directory containing
promptfooconfig.yaml, then run:- npx
- npm
- brew
npx promptfoo@latest evalpromptfoo evalpromptfoo evalThis tests every prompt, model, and test case.
-
Review outputs: After the evaluation is complete, open the web viewer to review the outputs:
- npx
- npm
- brew
npx promptfoo@latest viewpromptfoo viewpromptfoo view
Asserts
The YAML configuration format runs each prompt through a series of test cases and checks if they meet the specified asserts.
Asserts are optional. Many people get value out of reviewing outputs manually, and the web UI helps facilitate this.
See the Configuration docs for a detailed guide.
Examples
The examples below cover a few common eval patterns: prompt quality, model quality, RAG quality, and agent quality.
Prompt quality
In this example, we evaluate whether adding adjectives to the personality of an assistant bot affects the responses.
You can quickly set up this example by running:
- npx
- npm
- brew
npx promptfoo@latest init --example eval-self-grading
promptfoo init --example eval-self-grading
promptfoo init --example eval-self-grading
Show YAML file for this example
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: Automatic response evaluation using LLM rubric scoring
# Load prompts
prompts:
- file://prompts.txt
providers:
- openai:chat:gpt-5.4
defaultTest:
assert:
- type: llm-rubric
value: Do not mention that you are an AI or chat assistant
- type: javascript
# Shorter is better
value: Math.max(0, Math.min(1, 1 - (output.length - 100) / 900));
tests:
- vars:
name: Bob
question: Can you help me find a specific product on your website?
- vars:
name: Jane
question: Do you have any promotions or discounts currently available?
- vars:
name: Ben
question: Can you check the availability of a product at a specific store location?
- vars:
name: Dave
question: What are your shipping and return policies?
- vars:
name: Jim
question: Can you provide more information about the product specifications or features?
- vars:
name: Alice
question: Can you recommend products that are similar to what I've been looking at?
- vars:
name: Sophie
question: Do you have any recommendations for products that are currently popular or trending?
- vars:
name: Jessie
question: How can I track my order after it has been shipped?
- vars:
name: Kim
question: What payment methods do you accept?
- vars:
name: Emily
question: Can you help me with a problem I'm having with my account or order?
From the newly created directory, run npx promptfoo@latest eval to execute this example:

This command will evaluate the prompts, substituting variable values, and output the results in your terminal.
You can also output a spreadsheet, JSON, YAML or HTML.
Model quality
In this next example, we evaluate the difference between GPT-5.4 and GPT-5.4 Mini outputs for a given prompt:
You can quickly set up this example by running:
- npx
- npm
- brew
npx promptfoo@latest init --example compare-openai-models
promptfoo init --example compare-openai-models
promptfoo init --example compare-openai-models
Show YAML file for this example
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: Comparing OpenAI flagship and mini models performance on riddles
prompts:
- 'Solve this riddle: {{riddle}}'
providers:
- openai:chat:gpt-5.4
- openai:chat:gpt-5.4-mini
defaultTest:
assert:
# Inference should always cost less than this (USD)
- type: cost
threshold: 0.002
# Inference should always be faster than this (milliseconds)
- type: latency
threshold: 3000
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
# Make sure the LLM output contains this word
- type: contains
value: echo
# Use model-graded assertions to enforce free-form instructions
- type: llm-rubric
value: Do not apologize
- vars:
riddle: "You see a boat filled with people. It has not sunk, but when you look again you don't see a single person on the boat. Why?"
assert:
- type: llm-rubric
value: explains that there are no single people (they are all married)
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
assert:
- type: contains
value: darkness
- vars:
riddle: >-
I have keys but no locks. I have space but no room. You can enter, but
can't go outside. What am I?
- vars:
riddle: >-
I am not alive, but I grow; I don't have lungs, but I need air; I don't
have a mouth, but water kills me. What am I?
- vars:
riddle: What can travel around the world while staying in a corner?
- vars:
riddle: Forward I am heavy, but backward I am not. What am I?
- vars:
riddle: >-
The person who makes it, sells it. The person who buys it, never uses
it. The person who uses it, doesn't know they're using it. What is it?
- vars:
riddle: I can be cracked, made, told, and played. What am I?
- vars:
riddle: What has keys but can't open locks?
- vars:
riddle: >-
I'm light as a feather, yet the strongest person can't hold me for much
more than a minute. What am I?
- vars:
riddle: >-
I can fly without wings, I can cry without eyes. Whenever I go, darkness
follows me. What am I?
- vars:
riddle: >-
I am taken from a mine, and shut up in a wooden case, from which I am
never released, and yet I am used by almost every person. What am I?
- vars:
riddle: >-
David's father has three sons: Snap, Crackle, and _____? What is the
name of the third son?
- vars:
riddle: >-
I am light as a feather, but even the world's strongest man couldn't
hold me for much longer than a minute. What am I?
Navigate to the newly created directory and run npx promptfoo@latest eval or promptfoo eval. Also note that you can override parameters directly from the command line.
For example, if you run this command:
- npx
- npm
- brew
npx promptfoo@latest eval -r google:gemini-3-pro-preview google:gemini-2.5-pro
promptfoo eval -r google:gemini-3-pro-preview google:gemini-2.5-pro
promptfoo eval -r google:gemini-3-pro-preview google:gemini-2.5-pro
It produces the following table, with Gemini models replacing the GPT models in the config:

A similar approach can be used to run other model comparisons. For example, you can:
- Compare GPT-5.4 reasoning effort settings (see GPT reasoning effort comparison)
- Compare models with different temperatures (see GPT temperature comparison)
- Compare open-source models (see Comparing Open-Source Models)
- Compare Retrieval-Augmented Generation (RAG) with LangChain vs. regular GPT (see LangChain example)
RAG quality
In this example, we evaluate whether RAG outputs are factual, relevant, and grounded in the retrieved context.
You can quickly set up this example by running:
- npx
- npm
- brew
npx promptfoo@latest init --example eval-rag
promptfoo init --example eval-rag
promptfoo init --example eval-rag
From the newly created directory, run npx promptfoo@latest eval or promptfoo eval to grade outputs on factuality, answer relevance, context recall, context relevance, and context faithfulness. For a deeper walkthrough, see the RAG evaluation guide.
Agent quality
In this example, we evaluate an OpenAI Agents SDK workflow that uses tools for dice rolls, inventory checks, scene descriptions, and character stats.
You can quickly set up this example by running:
- npx
- npm
- brew
npx promptfoo@latest init --example openai-agents-basic
promptfoo init --example openai-agents-basic
promptfoo init --example openai-agents-basic
From the newly created directory, run npm install, then npx promptfoo@latest eval or promptfoo eval to test tool use and response quality across multi-turn scenarios. For task completion and trajectory checks, see the agent evaluation guide and tracing docs.
Next steps
Now that you've run your first eval, here are some ways to go deeper:
Customize your setup:
- Configuration guide - Detailed walkthrough of all config options
- Providers documentation - All 60+ supported AI models and services
- Assertions & Metrics - Automatically grade outputs on a pass/fail basis
Explore use cases:
- Agent evaluation - Test whether agents complete tasks and follow expected trajectories
- RAG evaluation - Test retrieval-augmented generation pipelines
- Red teaming quickstart - Scan your LLM app for security vulnerabilities
- CI/CD integration - Run evals automatically on every PR
Learn from examples:
- More examples in our GitHub repository