Assertions & metrics
Assertions are used to compare the LLM output against expected values or conditions. While assertions are not required to run an eval, they are a useful way to automate your analysis.
Different types of assertions can be used to validate the output in various ways, such as checking for equality, JSON structure, similarity, or custom functions.
In machine learning, "Accuracy" is a metric that measures the proportion of correct predictions made by a model out of the total number of predictions. With promptfoo, accuracy is defined as the proportion of prompts that produce the expected or desired output.
Using assertions
To use assertions in your test cases, add an assert property to the test case with an array of assertion objects. Each assertion object should have a type property indicating the assertion type and any additional properties required for that assertion type.
For a quick reference to available checks, jump to Assertion types.
Example:
tests:
- description: 'Test if output is equal to the expected value'
vars:
example: 'Hello, World!'
assert:
- type: equals
value: 'Hello, World!'
Assertion properties
| Property | Type | Required | Description |
|---|---|---|---|
| type | string | Yes | Type of assertion |
| value | string | No | The expected value, if applicable |
| threshold | number | No | The threshold value, applicable only to certain types such as similar, cost, javascript, python, ruby |
| weight | number | No | How heavily to weigh the assertion. Defaults to 1.0 |
| provider | string | No | Some assertions (similarity, llm-rubric, model-graded-*) require an LLM provider |
| rubricPrompt | string | string[] | No | Model-graded LLM prompt |
| config | object | No | External mapping of arbitrary strings to values passed to custom javascript/python/ruby assertions |
| transform | string | Function | No | Process the output before running the assertion. Accepts a string expression, file:// reference, or a function when using the Node.js package. See Transformations |
| metric | string | No | Tag that appears in the web UI as a named metric |
| contextTransform | string | Function | No | Javascript expression or function to dynamically construct context for context-based assertions. See Context Transform for more details. |
Grouping assertions via Assertion Sets
Assertions can be grouped together using an assert-set.
Example:
tests:
- description: 'Test that the output is cheap and fast'
vars:
example: 'Hello, World!'
assert:
- type: assert-set
assert:
- type: cost
threshold: 0.001
- type: latency
threshold: 200
In the above example if all assertions of the assert-set pass the entire assert-set passes.
There are cases where you may only need a certain number of assertions to pass. Here you can use threshold.
Example - if one of two assertions need to pass or 50%:
tests:
- description: 'Test that the output is cheap or fast'
vars:
example: 'Hello, World!'
assert:
- type: assert-set
threshold: 0.5
assert:
- type: cost
threshold: 0.001
- type: latency
threshold: 200
Assertion Set properties
| Property | Type | Required | Description |
|---|---|---|---|
| type | string | Yes | Must be assert-set |
| assert | array of asserts | Yes | Assertions to be run for the set |
| threshold | number | No | Success threshold for the assert-set. Ex. 1 out of 4 equal weights assertions need to pass. Threshold should be 0.25 |
| weight | number | No | How heavily to weigh the assertion set within test assertions. Defaults to 1.0 |
| metric | string | No | Metric name for this assertion set within the test |
Assertion types
Deterministic eval metrics
These metrics are programmatic tests that are run on LLM output. See all details
| Assertion Type | Returns true if... |
|---|---|
| equals | output matches exactly |
| contains | output contains a string or number as text |
| icontains | output contains a string or number as text, case insensitive |
| regex | output matches regex |
| starts-with | output starts with string |
| contains-any | output contains any of the listed substrings |
| contains-all | output contains all list of substrings |
| icontains-any | output contains any of the listed substrings, case insensitive |
| icontains-all | output contains all list of substrings, case insensitive |
| is-json | output is valid json (optional json schema validation) |
| contains-json | output contains valid json (optional json schema validation) |
| contains-html | output contains HTML content |
| is-html | output is valid HTML |
| is-sql | output is a non-empty valid SQL statement |
| contains-sql | output is valid SQL or contains a valid SQL code block |
| is-xml | output is a supported well-formed XML document |
| contains-xml | output contains valid xml fragment(s) |
| is-refusal | output indicates the model refused to perform the task |
| javascript | provided Javascript function validates the output |
| python | provided Python function validates the output |
| ruby | provided Ruby function validates the output |
| webhook | provided webhook returns {pass: true} |
| rouge-n | Rouge-N score is above a given threshold (default 0.75) |
| bleu | BLEU score is above a given threshold (default 0.5) |
| gleu | GLEU score is above a given threshold (default 0.5) |
| levenshtein | Levenshtein distance is below a threshold |
| latency | Latency is below a threshold (milliseconds) |
| meteor | METEOR score is above a given threshold (default 0.5) |
| perplexity | Perplexity is below a threshold |
| perplexity-score | Normalized perplexity |
| cost | Cost is below a threshold (for models with cost info such as GPT) |
| is-valid-function-call | Ensure that the function call matches the function's JSON schema |
| is-valid-openai-function-call | Ensure that the function call matches the function's JSON schema |
| is-valid-openai-tools-call | Ensure all tool calls match the tools JSON schema |
| trace-span-count | Count spans matching patterns with min/max thresholds |
| trace-span-duration | Check span durations with percentile support |
| trace-error-spans | Detect errors in traces by status codes, attributes, and messages |
| skill-used | Ensure normalized provider skill metadata includes expected skills |
| trajectory:tool-used | Ensure a traced agent trajectory used specific tools |
| trajectory:tool-args-match | Ensure traced tool calls used the expected arguments |
| trajectory:tool-sequence | Ensure traced tool usage happened in the expected order |
| trajectory:step-count | Count normalized trajectory steps by type or name pattern |
| guardrails | Ensure that the output does not contain harmful content |
Every test type can be negated by prepending not-. For example, not-equals or not-regex.
Model-assisted eval metrics
These metrics are model-assisted, and rely on LLMs or other machine learning models.
See Model-graded evals, classification, and similarity docs for more information.
| Assertion Type | Method |
|---|---|
| similar | Embeddings and cosine similarity are above a threshold |
| classifier | Run LLM output through a classifier |
| moderation | Check output against safety policies and include provider-reported usage metrics |
| llm-rubric | LLM output matches a given rubric, using a Language Model to grade output |
| g-eval | Chain-of-thought evaluation based on custom criteria using the G-Eval framework |
| answer-relevance | Ensure that LLM output is related to original query |
| context-faithfulness | Ensure that LLM output uses the context |
| context-recall | Ensure that ground truth appears in context |
| context-relevance | Ensure that context is relevant to original query |
| conversation-relevance | Ensure that responses remain relevant throughout a conversation |
| trajectory:goal-success | Use an LLM judge to decide whether the traced agent run achieved its goal |
| factuality | LLM output adheres to the given facts, using Factuality method from OpenAI eval |
| model-graded-closedqa | LLM output adheres to given criteria, using Closed QA method from OpenAI eval |
| pi | Alternative scoring approach that uses a dedicated model for evaluating criteria |
| select-best | Compare multiple outputs for a test case and pick the best one |
| max-score | Select output with highest aggregate score from other assertions |
Weighted assertions
In some cases, you might want to assign different weights to your assertions depending on their importance. The weight property is a number that determines the relative importance of the assertion. The default weight is 1.
The final score of the test case is calculated as the weighted average of the scores of all assertions, where the weights are the weight values of the assertions.
Here's an example:
tests:
assert:
- type: equals
value: 'Hello world'
weight: 2
- type: contains
value: 'world'
weight: 1
In this example, the equals assertion is twice as important as the contains assertion.
If the LLM output is Goodbye world, the equals assertion fails but the contains assertion passes, and the final score is 0.33 (1/3).
Setting a score requirement
Test cases support an optional threshold property. If set, the pass/fail status of a test case is determined by whether the combined weighted score of all assertions is greater than or equal to the threshold value.
For example:
tests:
threshold: 0.5
assert:
- type: equals
value: 'Hello world'
weight: 2
- type: contains
value: 'world'
weight: 1
If the LLM outputs Goodbye world, the equals assertion fails but the contains assertion passes and the final score is 0.33. Because this is below the 0.5 threshold, the test case fails. If the threshold were lowered to 0.2, the test case would succeed.
A threshold of 0 makes the test case pass regardless of individual assertion failures, since the combined score is always at least 0. Use it to collect assertion scores without letting any single failure fail the test. The same applies to an assert-set threshold.
If weight is set to 0, the assertion automatically passes.
Custom assertion scoring
By default, test cases use weighted averaging to combine assertion scores. You can define custom scoring functions to implement more complex logic, such as:
- Failing if any critical metric falls below a threshold
- Implementing non-linear scoring combinations
- Using different scoring logic for different test cases
Prerequisites
Custom scoring functions require named metrics. Each assertion must have a metric field:
assert:
- type: equals
value: 'Hello'
metric: accuracy
- type: contains
value: 'world'
metric: completeness
Configuration
Define scoring functions at two levels:
defaultTest:
assertScoringFunction: file://scoring.js # Global default
tests:
- description: 'Custom scoring for this test'
assertScoringFunction: file://custom.js # Test-specific override
The scoring function can be JavaScript or Python, referenced with file:// prefix. For named exports, use file://path/to/file.js:functionName.
Function Interface
type ScoringFunction = (
namedScores: Record<string, number>, // Map of metric names to scores (0-1)
context: {
threshold?: number; // Test case threshold if set
tokensUsed?: {
// Token usage if available
total: number;
prompt: number;
completion: number;
};
},
) => {
pass: boolean; // Whether the test case passes
score: number; // Final score (0-1)
reason: string; // Explanation of the score
};
When assertions use weight, each named score passed into the scoring function is already normalized as a weighted average. Eval outputs also include namedScoreWeights so downstream consumers can recover the weighted denominator when needed.
See the custom assertion scoring example for complete implementations in JavaScript and Python.
Load assertions from external file
Raw files
The value of an assertion can be loaded directly from a file using the file:// syntax:
- assert:
- type: contains
value: file://gettysburg_address.txt
Javascript
If the file ends in .js, the Javascript is executed:
- assert:
- type: javascript
value: file://path/to/assert.js
The type definition is:
type AssertionValueFunctionContext = {
prompt: string | undefined;
vars: Record<string, string | object>;
test: AtomicTestCase<Record<string, string | object>>;
logProbs: number[] | undefined;
config?: Record<string, any>;
provider: ApiProvider | undefined;
providerResponse: ProviderResponse | undefined;
metadata?: ProviderResponse['metadata']; // Shortcut to providerResponse?.metadata
};
type AssertionResponse = string | boolean | number | GradingResult;
type AssertFunction = (output: string, context: AssertionValueFunctionContext) => AssertionResponse;
Here's an example assert.js:
module.exports = (output, { vars }) => {
console.log(`Received ${output} using variables ${JSON.stringify(vars)}`);
return {
pass: true,
score: 0.5,
reason: 'Some custom reason',
};
};
You can also use Javascript files in non-javascript-type asserts. For example, using a Javascript file in a contains assertion will check that the output contains the string returned by Javascript.
Python
If the file ends in .py, the Python is executed:
- assert:
- type: python
value: file://path/to/assert.py
The assertion expects an output that is bool, float, or a JSON GradingResult.
For example:
import sys
import json
output = sys.argv[1]
context = json.loads(sys.argv[2])
# Use `output` and `context['vars']` to determine result ...
print(json.dumps({
'pass': False,
'score': 0.5,
'reason': 'Some custom reason',
}))
Load assertions from CSV
The Tests file is an optional format that lets you specify test cases outside of the main config file.
To add an assertion to a test case in a vars file, use the special __expected column.
Here's an example tests.csv:
| text | __expected |
|---|---|
| Hello, world! | Bonjour le monde |
| Goodbye, everyone! | fn:output.includes('Au revoir'); |
| I am a pineapple | grade:doesn't reference any fruits besides pineapple |
All assertion types can be used in __expected. The column supports exactly one assertion.
Assertion string syntax
The general format is type:value or type(threshold):value. Values without a prefix default to equals.
| Syntax | Type | Example |
|---|---|---|
value | equals | Paris |
contains:value | contains | contains:Paris |
icontains:value | icontains | icontains:paris |
contains-any:value1,value2 | contains-any | contains-any:Paris,London |
contains-all:value1,value2 | contains-all | contains-all:Paris,France |
starts-with:value | starts-with | starts-with:The answer |
regex:pattern | regex | regex:^Hello.*world$ |
is-json | is-json | is-json |
contains-json | contains-json | contains-json |
similar(threshold):value | similar | similar(0.8):Hello world |
llm-rubric:criteria | llm-rubric | llm-rubric:Is helpful and accurate |
grade:criteria | llm-rubric | grade:Does not mention being an AI |
factuality:reference | factuality | factuality:Paris is the capital of France |
javascript:code | javascript | javascript:output.length < 100 |
fn:code | javascript | fn:output.includes('hello') |
python:code | python | python:len(output) > 10 |
file://path | External file | file://assertions/custom.js |
not-type:value | Negated | not-contains:error |
levenshtein(N):value | levenshtein | levenshtein(5):expected text |
When the __expected field is provided, the success and failure statistics in the evaluation summary will be based on whether the expected criteria are met.
To run multiple assertions, use column names __expected1, __expected2, __expected3, etc.
For more advanced test cases, we recommend using a testing framework like Jest or Vitest or Mocha and using promptfoo as a library.
Reusing assertions with templates
If you have a set of common assertions that you want to apply to multiple test cases, you can create assertion templates and reuse them across your configuration.
assertionTemplates:
containsMentalHealth:
type: javascript
value: output.toLowerCase().includes('mental health')
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-5.5
- localai:chat:vicuna
tests:
- vars:
input: Tell me about the benefits of exercise.
assert:
- $ref: "#/assertionTemplates/containsMentalHealth"
- vars:
input: How can I improve my well-being?
assert:
- $ref: "#/assertionTemplates/containsMentalHealth"
In this example, the containsMentalHealth assertion template is defined at the top of the configuration file and then reused in two test cases. This approach helps maintain consistency and reduces duplication in your configuration.
Defining named metrics
Each assertion supports a metric field that allows you to tag the result however you like. Use this feature to combine related assertions into aggregate metrics.
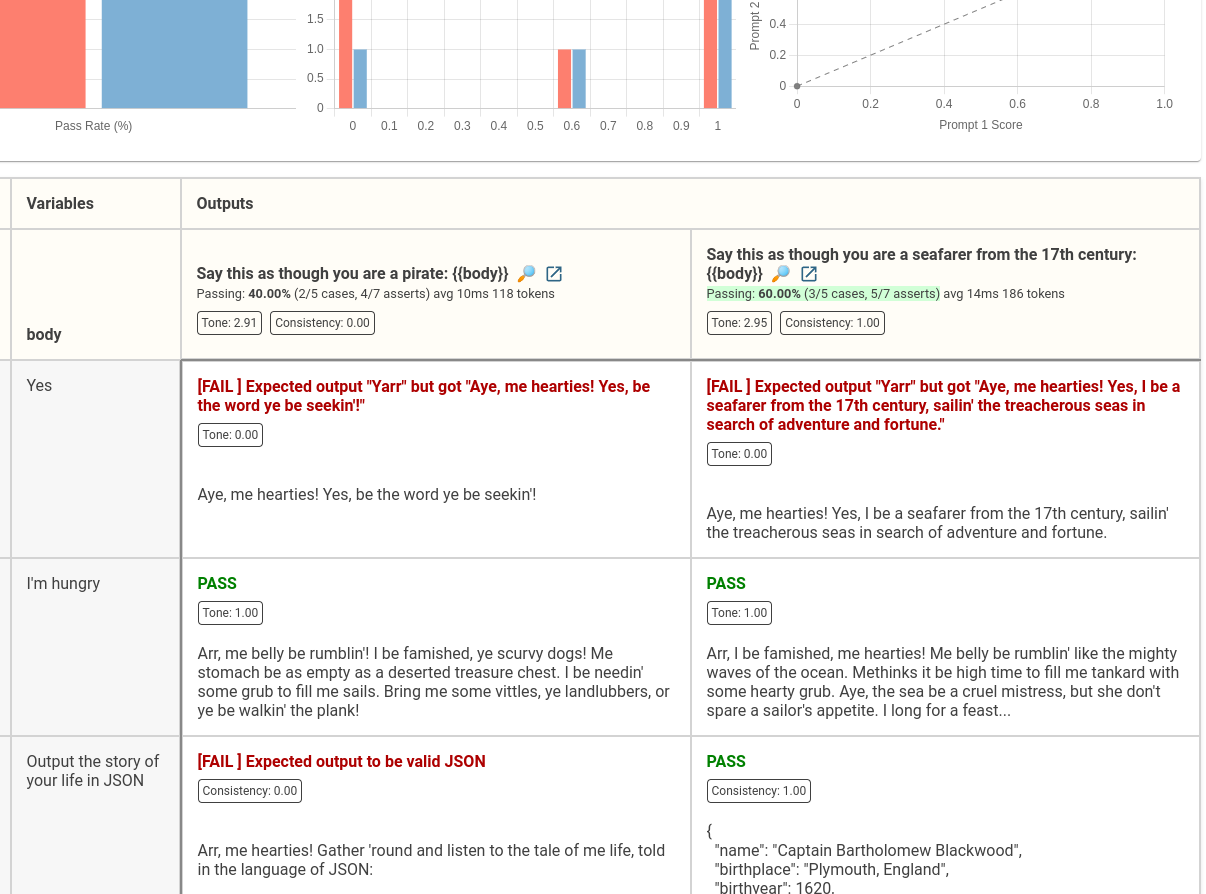
For example, these asserts will aggregate results into two metrics, Tone and Consistency.
tests:
- assert:
- type: equals
value: Yarr
metric: Tone
- assert:
- type: icontains
value: grub
metric: Tone
- assert:
- type: is-json
metric: Consistency
- assert:
- type: python
value: max(0, len(output) - 300)
metric: Consistency
- type: similar
value: Ahoy, world
metric: Tone
- assert:
- type: llm-rubric
value: Is spoken like a pirate
metric: Tone
These metrics will be shown in the UI:
Creating derived metrics
Derived metrics calculate composite scores from your named assertions after evaluation completes. Use them for metrics like F1 scores, weighted averages, or custom scoring formulas.
Add a derivedMetrics array to your configuration:
derivedMetrics:
- name: 'f1_score'
value: '2 * precision * recall / (precision + recall)'
Each derived metric requires:
- name: The metric identifier
- value: A mathematical expression or JavaScript function
Derived metrics are initialized to 0 and calculated per prompt. Errors are logged at debug level.
Mathematical expressions
Use mathjs syntax for calculations:
derivedMetrics:
- name: 'weighted_score'
value: 'accuracy * 0.6 + relevance * 0.4'
- name: 'harmonic_mean'
value: '3 / (1/accuracy + 1/relevance + 1/coherence)'
JavaScript functions
For complex logic:
derivedMetrics:
- name: 'adaptive_score'
value: |
function(namedScores, evalStep) {
const { accuracy = 0, speed = 0 } = namedScores;
if (evalStep.tokensUsed?.total > 1000) {
return accuracy * 0.8; // Penalize verbose responses
}
return accuracy * 0.6 + speed * 0.4;
}
Example: F1 score
defaultTest:
assert:
- type: javascript
value: output.sentiment === 'positive' && context.vars.expected === 'positive' ? 1 : 0
metric: true_positives
weight: 0
- type: javascript
value: output.sentiment === 'positive' && context.vars.expected === 'negative' ? 1 : 0
metric: false_positives
weight: 0
- type: javascript
value: output.sentiment === 'negative' && context.vars.expected === 'positive' ? 1 : 0
metric: false_negatives
weight: 0
derivedMetrics:
- name: precision
value: 'true_positives / (true_positives + false_positives)'
- name: recall
value: 'true_positives / (true_positives + false_negatives)'
- name: f1_score
value: '2 * true_positives / (2 * true_positives + false_positives + false_negatives)'
Metrics are calculated in order, so later metrics can reference earlier ones:
derivedMetrics:
- name: base_score
value: '(accuracy + relevance) / 2'
- name: final_score
value: 'base_score * confidence_multiplier'
Calculating averages with __count
For metrics where you need the average across test cases (like Mean Absolute Percentage Error), use the built-in __count variable:
defaultTest:
assert:
- type: javascript
value: |
const actual = context.vars.actual_value;
const predicted = parseFloat(output);
return Math.abs(actual - predicted) / actual;
metric: APE
weight: 0
derivedMetrics:
# MAPE = Mean Absolute Percentage Error
- name: MAPE
value: 'APE / __count'
The __count variable contains the number of test evals for the current prompt-provider combination. With multiple providers, each provider gets its own separate metrics tracked independently. This is useful when:
- Each test case produces a value that gets summed (like error metrics)
- You want to display the average instead of the total
For JavaScript functions, __count is available in the namedScores object:
derivedMetrics:
- name: 'average_error'
value: |
function(namedScores, evalStep) {
return namedScores.total_error / namedScores.__count;
}
Notes
- Missing metrics default to 0
- The
__countvariable is per prompt-provider combination (number of test cases) - Functions receive a copy of the context - return values, don't mutate
- To avoid division by zero:
value: 'numerator / (denominator + 0.0001)' - Debug errors with:
LOG_LEVEL=debug promptfoo eval - No circular dependency protection - order your metrics carefully
Derived metrics appear in all outputs alongside regular metrics - in the web UI metrics column, JSON namedScores, and CSV columns.
See also:
- Named metrics example - Basic named metrics usage
- F-score example - Complete F1 score implementation
- MathJS documentation - Expression syntax reference
Running assertions directly on outputs
If you already have LLM outputs and want to run assertions on them, the eval command supports standalone assertion files.
Put your outputs in a JSON string array, like this output.json:
["Hello world", "Greetings, planet", "Salutations, Earth"]
And create a list of assertions (asserts.yaml):
- type: icontains
value: hello
- type: javascript
value: 1 / (output.length + 1) # prefer shorter outputs
- type: model-graded-closedqa
value: ensure that the output contains a greeting
Then run the eval command:
promptfoo eval --assertions asserts.yaml --model-outputs outputs.json
Tagging outputs
Promptfoo accepts a slightly more complex JSON structure that includes an output field for the model's output and a tags field for the associated tags. These tags are shown in the web UI as a comma-separated list. It's useful if you want to keep track of certain output attributes:
[
{ "output": "Hello world", "tags": ["foo", "bar"] },
{ "output": "Greetings, planet", "tags": ["baz", "abc"] },
{ "output": "Salutations, Earth", "tags": ["def", "ghi"] }
]
Processing and formatting outputs
If you need to do any processing/formatting of outputs, use a Javascript provider, Python provider, or custom script.