Release Notes
Full release history for Promptfoo open source can be found on GitHub.
January 2026 Release Highlights
This month we shipped adaptive rate limiting, Transformers.js for local inference, telecom red team plugins, and video generation providers.
Evals
Providers
New Providers
- Transformers.js - Run models locally in Node.js or browser using Hugging Face's Transformers.js
- Vercel AI Gateway - Route requests through Vercel's AI gateway
- Cloudflare AI Gateway - Route requests through Cloudflare's AI gateway
Video Generation
- AWS Bedrock Video - Nova Reel and Luma Ray 2 video generation
- Azure AI Foundry Video - Sora video generation via Azure
Provider Updates
- HTTP provider - Native session endpoint support for stateful conversations
- xAI Voice - Added
apiBaseUrl,websocketUrloverride, and function call support - OpenCode SDK - Updated to v1.1.x with new features
- OpenAI Codex - Integrated tracing and collaboration_mode support
- WatsonX - Enhanced parameters and chat support
Assertions
- word-count - New assertion type for validating response word counts
__countvariable - Use in derived metrics for computing averages
UI & Developer Experience
- Provider config hover - View provider configuration details on hover in eval results
- Session ID column -
metadata.sessionIdsurfaced as a variable column in tables and exports - User-rated filter - Filter to show only manually rated results
promptfoo logs- New command for viewing log files directly
Rate Limiting
- Adaptive rate limit scheduler - Automatically adjusts concurrency based on provider rate limits and response headers
Configuration
- Test-level prompts filter - Filter prompts at the individual test case level
- Providers filter - Filter providers at the test case level
- Per-test structured output - Configure structured outputs at the test case level
- Environment variables in paths - Use
$VARsyntax in file paths - Multiple
--env-fileflags - Load multiple environment files
Code Scanning
- Fork PR support - Scan pull requests from forks
- Comment-triggered scans - Trigger scans via PR comments
Model Audit
- Auto-sharing flags - Use
--shareand--no-shareto control cloud sharing
Red Teaming
New Plugins
- Telecom - Industry-specific red team plugins for telecommunications AI systems
- RAG Source Attribution - Test whether RAG systems properly attribute sources in their responses
Multi-Input Testing
Red team scans now support multiple input variables, allowing you to test systems with complex input structures.
Strategy Configuration
- numTests config - Cap the number of test cases generated per strategy
-d/--descriptionflag - Add descriptions toredteam generatecommands- Early scan stop - Scans stop early when plugins fail to generate test cases
Enterprise
Performance
- Automatic retries - Transient 5xx errors are automatically retried
- Python concurrency -
-jflag now propagates to Python worker pools
December 2025 Release Highlights
This month we shipped video generation providers, OWASP Agentic AI Top 10, xAI Voice Agent, and multi-modal attack strategies.
Evals
Providers
Video Generation Providers
- OpenAI Sora - Generate videos with OpenAI's Sora model
- Google Veo - Generate videos with Google's Veo model
New Providers
- xAI Voice Agent - Voice agent API for audio interactions
- ElevenLabs - Text-to-speech and voice synthesis
- OpenCode SDK - OpenCode model provider
New Model Support
- GPT-5.2 - Latest GPT-5 series model
- Amazon Nova 2 - Nova 2 with reasoning capabilities
- Gemini 3 Flash Preview - Flash Preview with Vertex AI express mode
- Llama 3.2 Vision - Vision support via Bedrock InvokeModel API
- GPT Image 1.5 - Updated image generation model
- gpt-image-1-mini - Smaller image generation model
Provider Updates
- Browser provider - Multi-turn session persistence
- Vertex AI - Streaming option for Model Armor
- Gemini - Native image generation support
- Claude Agent SDK - Updated to v0.1.60 with betas and dontAsk support
- OpenAI Codex SDK - Updated to v0.65.0
UI & Developer Experience
- Redesigned reports - Improved visualization of risk categories
- Evaluation duration - Display total evaluation time in the web UI
- Full grading prompt display - View complete grading prompts in the UI
- Wildcard prompt filters - Use wildcards when filtering prompts
Tracing
- OpenTelemetry integration - Native OTLP tracing with GenAI semantic conventions
- Protobuf support - OTLP trace ingestion via protobuf format
Configuration
- Configurable base path - Set custom base paths for the server
--extensionCLI flag - Load extensions via command line- afterAll hook enhancement - Improved extension hook capabilities
- Shareable URLs in API - Generate shareable URLs from the Node.js
evaluate()API
Authentication
- Interactive team selection - Select team during login flow
- MCP OAuth - OAuth authentication with proactive token refresh
Red Teaming
OWASP Agentic AI
- OWASP Top 10 for Agentic Applications - Complete T1-T15 threat mapping for AI agents
- OWASP API Security Top 10 - Example configuration for API security testing
Multi-Modal Attacks
- Multi-modal layer strategy - Chain audio and image attacks in layer strategies
Strategy Improvements
- Plugin selection for strategies - Change which plugin is used for strategy test case generation
- Tiered severity for SSRF - Grading now uses tiered severity levels
- HTTP authentication options - Configure authentication for HTTP targets
- Browser job persistence - Persist jobs for browser-based evaluations
- Tracing for Hydra - OpenTelemetry tracing support in Hydra and IterativeMeta
Other Improvements
- Contexts for app states - Test different application states with context configuration
- Retry strategy - Automatically retry failed test cases
- Validate target improvements - Better output when validating targets
Enterprise
Assertions
- Tool calling F1 score - Evaluate tool calling accuracy with F1 metrics
Bedrock
- Configurable numberOfResults - Set result count for Bedrock Knowledge Base queries
November 2025 Release Highlights
This month we shipped Hydra multi-turn strategy, code scanning, Claude Opus 4.5, and VS Code extension.
Evals
Providers
New Providers
- OpenAI ChatKit - ChatKit provider for conversational AI
- OpenAI Codex SDK - Codex SDK for code generation
- AWS Bedrock Converse API - Converse API for multi-turn conversations
New Model Support
- Claude Opus 4.5 - Support across Anthropic, Google Vertex AI, and AWS Bedrock
- GPT-5.1 - Latest GPT-5 series update
- Gemini 3 Pro - Pro model with thinking configuration
- Groq reasoning models - Reasoning models with Responses API and built-in tools
- xAI Responses API - Responses API with Agent Tools support
Provider Updates
- Anthropic - Structured outputs support
- Claude Agent SDK - Plugin support and additional options
- Vertex AI - Google Cloud Model Armor support
- Azure - Comprehensive model support, verbosity and isReasoningModel config
- Simulated User - initialMessages support with variable templating
Assertions
- Web search assertion - Assert on web search results
- Dot product and euclidean distance - New similarity metrics for embeddings
UI & Developer Experience
- Eval results filter permalinking - Share filtered views with URLs
- Metadata value autocomplete - Autocomplete for metadata filter values
- Rendered assertion values - View rendered assertion values in the Evaluation tab
- Eval copy functionality - Copy evaluations to new configurations
- Improved delete UX - Confirmation dialog and smart navigation
- Total and filtered metrics - Display both total and filtered counts
Configuration
- XLSX/XLS support - Load test cases from Excel files
- Executable prompt scripts - Run scripts as prompts
- Compliance frameworks in config - Set specific compliance frameworks
- Tool definitions from files - Load tool definitions from Python/JavaScript files
- Local config override - Override cloud provider configurations locally
Integrations
- Microsoft SharePoint - Load datasets from SharePoint
- Cloud trace sharing - Share trace data to Promptfoo Cloud
Model Audit
- Revision tracking - Track HuggingFace Git SHAs for model scans
- Deduplication - Skip previously scanned models by content hash
Red Teaming
Hydra Strategy
Hydra is a new advanced multi-turn red team strategy that adapts dynamically based on target responses, using conversation techniques to probe for vulnerabilities.
Code Scanning
Code scanning analyzes your codebase for potential AI security issues before they reach production.
VS Code Extension
Install the VS Code red team extension to run security scans directly from your editor.
New Plugins
Plugin Improvements
- Custom policy generation - Generate policies from natural language descriptions
- Domain-specific risk suites - Organized vertical suites for different industries
- Granular harmful subcategories - Show detailed metrics for harmful content plugins
- VLGuard update - Now uses MIT-licensed dataset
Grading Improvements
- Grading guidance config - Add extra grading rules via configuration
- Grading guidance UI - Configure plugin-specific grading rules in the UI
- Timestamp context - All grading rubrics now include timestamp context
Strategy Improvements
- Layer strategy UI - Comprehensive configuration interface for layer strategies
- Strategy test generation - Generate test cases for strategies in the UI
- OWASP Agentic Top 10 preset - Preset with appropriate plugins and strategies
- Trace context - Strategies now use trace context for debugging
Enterprise
Provider Management
- Server-side provider list - Customize available providers from the server
Audio
- OpenAI audio transcription - Transcribe audio for analysis
October 2025 Release Highlights
This month we shipped jailbreak:meta red team strategy, remediation reports, and Postman/cURL import for HTTP targets.
Evals
Providers
New Providers
- OpenAI Agents SDK - Agents, tools, handoffs, and OTLP tracing
- Claude Agent SDK - Anthropic agent framework
- Azure AI Foundry Agents - Azure AI agent framework
- Ruby - Execute Ruby scripts as providers
- Snowflake Cortex - Snowflake LLM provider
- Slack - Test Slack bots
New Model Support
Provider Updates
- Python provider - Persistent worker pools for 10-100x performance improvement
- WebSocket provider - Stream multiple responses
- Ollama - Function calling and tool support
UI & Developer Experience
- Chat Playground redesign - New layout and response visualization
- Metric filtering with operators - Filter eval results using
eq,neq,gt,gte,lt,lte, andis_definedoperators - Keyboard navigation - Navigate eval results table with arrow keys and Enter
- Cached response latency - Latency measurements preserved when responses are cached
- File-based logging - Logs written to files instead of CLI streaming
Export & Integration
- SARIF export - Export vulnerability reports in SARIF format
- CSV exports - Added Strategy ID, Plugin ID, and Session IDs to CSV exports
Configuration
- MCP server configuration - Model Context Protocol server setup
Model Audit
- Revision tracking and deduplication - Track HuggingFace Git SHAs and content hashes
- Batch existence checks - Check if multiple models have already been scanned
Red Teaming
Remediation Reports
Remediation reports include:
- Executive summary - Overview of scan findings
- Prioritized action items - Recommendations ranked by severity and impact
- System prompt suggestions - Suggested prompt improvements
- Guardrail recommendations - Suggested guardrails
Access from any vulnerability report by clicking "View Remediation Report".
Red Team Strategies
jailbreak:meta
jailbreak:meta uses multiple AI agents to generate attacks. This single-shot strategy is up to 50% more effective than some multi-turn attacks.
Scan Template Enhancements
- Probe and runtime estimates - Display estimated probe count and runtime in scan templates
- Sample attack previews - Preview generated test cases when selecting plugins
HTTP Target Configuration
- Postman/cURL import - Auto-populate target connection details from curl commands or Postman request/response files
- Connection testing - Test HTTP connections and transforms in the setup UI
- Request transforms - Request transforms have parity with response transforms
Grading Guidance
Plugin-specific grading rules:
- Plugin-level customization - Add grading guidance for individual plugins
- Custom intent support - Grading guidance for custom intent plugins
- Atomic saves - Guidance and examples saved together
New Plugins
- Wordplay - Tests if systems can be tricked into generating profanity through wordplay like riddles and rhyming games
- COPPA - Tests if AI systems collect personal information from children without parental consent or age verification
- Data protection preset - Privacy and personal data handling tests
Other Strategies
- Authoritative Markup Injection - Tests vulnerability to malicious instructions embedded in markup
September 2025 Release Highlights
This month we shipped reusable custom policies, risk scoring, 8 new AI providers, and comprehensive enterprise features for security teams.
Evals
Providers
New Model Support
- Claude 4.5 Sonnet - Anthropic's latest model
- Claude web tools -
web_fetch_20250910andweb_search_20250305tool support - GPT-5 - GPT-5, GPT-5 Codex, and GPT-5 Mini
- OpenAI Realtime API - Full audio input/output support for GPT Realtime models
- Gemini 2.5 Flash - Flash and Flash-Lite model support
New Providers
- Nscale - Image generation provider
- CometAPI - 7 models with environment variable configuration
- Envoy AI Gateway - Route requests through Envoy gateway
- Meta Llama API - All 7 Meta Llama models including multimodal Llama 4
Provider Updates
- AWS Bedrock - Qwen models, OpenAI GPT models, API key authentication
- AWS Bedrock Agents - Agent Runtime support (renamed from AgentCore)
- AWS Bedrock inference profiles - Application-level inference profile configuration
- HTTP provider - TLS certificate configuration via web UI
- WebSocket provider - Custom endpoint URLs for OpenAI Realtime
- Ollama - Thinking parameter configuration
- Azure Responses -
azure:responsesprovider alias
Pause/Resume Evaluations
Use Ctrl+C to pause long-running evaluations and promptfoo eval --resume to continue later.
UI & Developer Experience
- Keyboard navigation - Navigate results table with keyboard shortcuts
- Bulk delete - Delete multiple eval results at once
- Unencrypted attack display - Show both encoded and decoded attack forms
- Passes-only filter - Filter to show only passing results
- Severity filtering - Filter by severity level
- Metadata exists operator - Filter by metadata field presence
- Highlight filtering - Filter results by highlighted content
- Persistent headers - Report page headers remain visible when scrolling
- Team switching - Switch teams from command line
Export & Integration
- Enhanced CSV exports - Includes latency, grader reason, and grader comment
- Log export -
promptfoo export logscreates tar.gz for debugging - Default cloud sharing - Auto-enable sharing when connected to Promptfoo Cloud
- CI progress reporting - Text-based milestone reporting for long-running evals
Configuration
- Context arrays - Pass context as array of strings (example)
- MCP preset - Pre-configured Model Context Protocol plugin set
Red Teaming
Reusable Custom Policies
Custom policies can now be saved to a library and reused across red team evaluations:
- Policy libraries - Create centralized security policy repositories
- CSV upload - Bulk import policies via CSV
- Severity levels - Assign severity (low/medium/high/critical) for filtering and prioritization
- Test generation - Generate sample test cases from policy definitions
Reference policies in your red team config:
redteam:
plugins:
- id: policy
config:
policy: 'internal-customer-data-protection'
Risk Scoring
Red team reports now include quantitative risk scores based on severity, probability, and impact:
- Overall risk score (0-10) for system security posture
- Risk by category - Scores for different vulnerability types
- Risk trends - Track improvement over time
- Visual heatmaps - Identify high-risk areas
Use risk scores to prioritize remediation and set CI/CD deployment gates.
New Plugins
- VLGuard - Multi-modal vision-language model safety testing
- Special Token Injection - ChatML tag vulnerability testing (
<|im_start|>,<|im_end|>) - Financial plugins - Confidential Disclosure, Counterfactual, Defamation, Impartiality, Misconduct
Strategies & Compliance
- Layer strategy - Chain multiple strategies in a single scan
- Threshold configuration - Set minimum pass scores for tests
- ISO 42001 compliance - Framework compliance mappings for AI governance
Enterprise
Team Management
- Flexible licensing - Pay only for the red team tests you run
- License tracking - Usage monitoring and optimization insights
- IDP mapping - Identity provider team and role mapping for SSO
- Session configuration - Timeout and inactivity settings
Audit & Compliance
- Audit logging UI - Comprehensive audit trails for webhooks, teams, providers, and user management
August 2025 Release Highlights
This month we added support for new models, model audit cloud sharing, and performance improvements.
Evals
Providers
New Model Support
- GPT-5 - Added support for OpenAI's GPT-5 model with advanced reasoning capabilities
- Claude Opus 4.1 - Support for Anthropic's latest Claude model
- xAI Grok Code Fast - Added xAI's Grok Code Fast model for coding tasks
Provider Updates
- Enhanced Vertex AI - Improved credential management and authentication
- Google AI Studio - Added default provider configurations for Google AI Studio models
Model Audit Cloud Sharing
Model audit results can now be shared to the cloud for team collaboration:
- Persistent audit history - Track security scans over time
- Team sharing - Share audit results across teams
- Centralized storage - Store audit reports in the cloud
- Path management - Remove recent scan paths from history
Enhanced Authentication
Added support for advanced authentication methods:
- Certificate storage - Store client certificates for mTLS authentication
- Signature authentication - Support for uploaded signature-based authentication
- Credential sanitization - Prevent credential exposure in debug logs
AI-Powered HTTP Configuration
Added auto-fill capabilities for HTTP provider setup to reduce configuration time and errors.
Performance Improvements
- HuggingFace dataset fetching - Improved speed and reliability for large datasets
- Error handling - Better diagnostic messages and retry suggestions
- UI improvements - Streamlined interfaces and progress indicators
Red Teaming
Medical Off-Label Use Plugin
Added Medical Off-Label Use Detection plugin to identify inappropriate pharmaceutical recommendations that could endanger patients.
Unverifiable Claims Plugin
Added Unverifiable Claims Detection plugin to test AI systems' susceptibility to generating fabricated but plausible-sounding claims.
MCP Agent Testing
Added MCP Agent example for red team testing with tool call results, demonstrating how to test AI systems that use Model Context Protocol.
July 2025 Release Highlights
This month we focused on expanding provider support, enhancing evaluation capabilities, and strengthening enterprise features to help you build more reliable and secure AI applications.
Evals
New Models / Providers
Expanded Provider Support
- Docker Model Runner - Run models in isolated Docker containers for better security and reproducibility
- MCP (Model Context Protocol) - Connect to MCP servers for enhanced AI capabilities
- Google Imagen - Generate images for multimodal testing scenarios
- AIMLAPI - Access various AI models through a unified interface
New Model Support
- Grok-4 - Advanced reasoning capabilities from xAI
- OpenAI Deep Research Models - o3-deep-research and o4-mini-deep-research for complex problem solving
- Enhanced Azure Provider - Added system prompt support for better control
Enhanced Capabilities
- LiteLLM Embeddings - Similarity testing and semantic search
- Google Vision - Image understanding for multimodal evaluations
- HTTP Provider Enhancements - Added support for JKS and PFX client certificates.
- Browser Provider - Connect to existing Chrome browser sessions via Chrome DevTools Protocol (CDP) for testing OAuth-authenticated applications
Assertion Improvements
- Context Transforms: Extract additional data from provider responses to use in assertions: context-based assertions. These are especially useful for evaluating RAG systems.
- Finish Reason Validation: Use finish-reason as an option in assertions to validate how AI model responses are terminated. This is useful for checking if the model completed naturally, hit token limits, triggered content filters, or made tool calls as expected.
- Tracing Assertions: Use your tracing and telemetry data in assertions: trace-span-count, trace-span-duration, and trace-error-spans
Other Features
- External Test Configuration - defaultTest can now load test cases from external files for easier management
Developer Experience Improvements
- Python Debugging - Use
import pdb; pdb.set_trace()in executed third-party Python scripts for easier debugging - Enhanced Search - Comprehensive metadata filtering to search results with search operators (equals, contains, not contains) and persistent button actions
Web UI Improvements
Enhanced Eval Results Page
We've significantly improved the evaluation results interface to handle large-scale testing more effectively:
-
First-Class Zooming Support - Zoom in and out of the eval results table to see more data at once or focus on specific details. This is especially useful when working with evaluations containing hundreds or thousands of test cases.
-
Advanced Metadata Filtering - Filter results using powerful search operators (equals, contains, not contains) with persistent button actions. Click on any metric pill in the results to instantly apply it as a filter, making it easier to drill down into specific failure modes or success patterns.
-
Improved Pagination - Enhanced pagination controls with "go to" functionality and better handling of large result sets. The UI now maintains scroll position and filter state as you navigate between pages.
-
Multi-Metric Filtering - Apply multiple filters simultaneously to find exactly the results you're looking for. For red team evaluations, you can now filter by both plugin and strategy to analyze specific attack vectors.
-
Performance Optimizations - Fixed horizontal scrolling issues, improved rendering performance for large tables, and optimized memory usage when dealing with extensive evaluation results.
These improvements make it much easier to analyze and understand evaluation results, especially for large-scale red teaming exercises or comprehensive test suites.
Red Teaming
Enterprise Features
- Regrade Red Team Scans - After adding grading rules, re-grade existing scans without re-running them. Once you've changed a grading system (pass/fail criteria, reasoning, etc.) you can re-grade existing eval results to measure the effect of those changes.
- Identity Provider Integration - Map teams and roles from your Identity Provider to automatically assign permissions
- MCP Proxy - Enterprise-grade security for MCP servers with access control and traffic monitoring for sensitive data
Strategies
New Agentic Multi-Turn Strategies
We've launched two powerful new agentic multi-turn red team strategies that adapt dynamically based on target responses:
-
Custom Strategy - Define your own red teaming strategies using natural language instructions. This groundbreaking feature lets you create sophisticated, domain-specific attack patterns without writing code. The AI agent interprets your instructions and executes multi-turn conversations tailored to your specific testing needs.
-
Mischievous User Strategy - Simulates an innocently mischievous user who plays subtle games with your AI agent through multi-turn conversations. This strategy uncovers vulnerabilities by mimicking real-world user behavior where users might push boundaries through playful or indirect approaches rather than direct attacks.
Both strategies leverage AI agents to conduct intelligent, adaptive conversations that evolve based on your system's responses, making them far more effective than static attack patterns.
Other Strategy Improvements
- HTTP Target Improvements - Enhanced test button now provides detailed error diagnostics, automatic retry suggestions, and context-aware fixes for common configuration issues like authentication failures, CORS errors, and malformed requests
June 2025 Release Highlights
This month we focused on enhancing observability, expanding provider support, and strengthening red team capabilities to help you build more reliable and secure AI applications.
Evals
Tracing
See Inside Your LLM Applications with OpenTelemetry
We've added OpenTelemetry tracing support to help you understand what's happening inside your AI applications. Previously, LLM applications were often "black boxes"—you could see inputs and outputs, but not what happened in between. Now you can visualize the entire execution flow, measure performance of individual steps, and quickly identify issues.
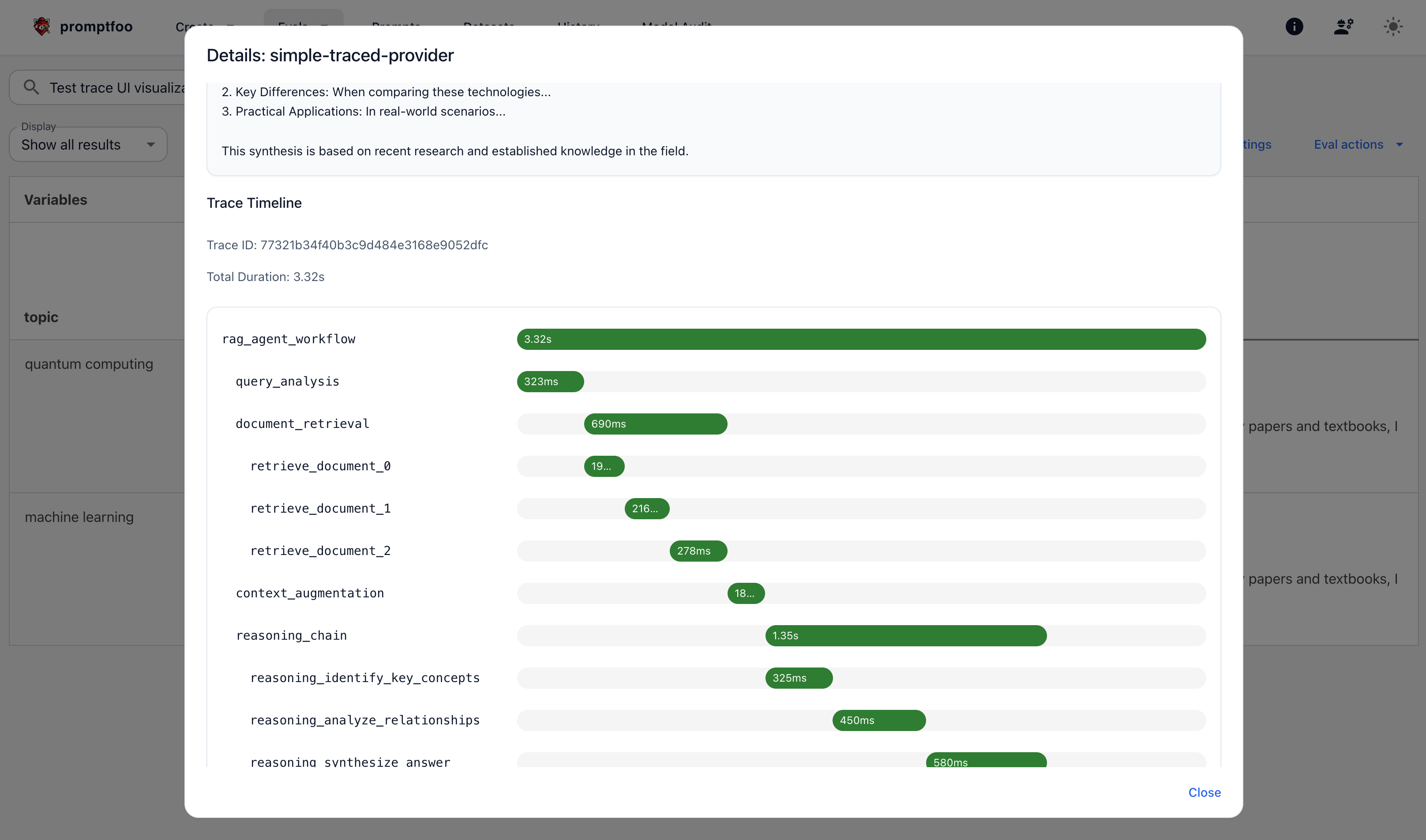
This is especially valuable for complex RAG pipelines or multi-step workflows where you need to identify performance bottlenecks or debug failures.
Use it when:
- Debugging slow RAG pipelines
- Optimizing multi-step agent workflows
- Understanding why certain requests fail
- Measuring performance across different providers
New Models / Providers
Expanded Audio and Multimodal Capabilities
As AI applications increasingly use voice interfaces and visual content, you need tools to evaluate these capabilities just as rigorously as text-based interactions. We've significantly expanded support for audio and multimodal AI:
-
Google Live Audio - Full audio generation with features like:
- Voice selection and customization
- Affective dialog for more natural conversations
- Real-time transcription
- Support for Gemini 2.0 Flash and native audio models
-
Hyperbolic Provider - New support for Hyperbolic's image and audio models, providing more options for multimodal evaluations
-
Helicone AI Gateway - Route requests through Helicone for enhanced monitoring and analytics
-
Mistral Magistral - Added support for Mistral's latest reasoning models
Other Features
Static Model Scanning with ModelAudit
Supply chain attacks through compromised models are a growing threat. We've significantly enhanced our static model security scanner to help you verify model integrity before deployment, checking for everything from malicious pickle files to subtle statistical anomalies that might indicate trojaned models.
New Web Interface: ModelAudit now includes a visual UI accessible at /model-audit when running promptfoo view:
- Visual file/directory selection with drag-and-drop support
- Real-time scanning progress with live updates
- Tabbed results display with severity color coding
- Scan history tracking
Expanded Format Support:
- SafeTensors - Support for Hugging Face's secure tensor format
- HuggingFace URLs - Scan models directly from HuggingFace without downloading
- Enhanced Binary Detection - Automatic format detection for
.binfiles (PyTorch, SafeTensors, etc.) - Weight Analysis - Statistical anomaly detection to identify potential backdoors
Security Improvements:
- Better detection of embedded executables (Windows PE, Linux ELF, macOS Mach-O)
- Path traversal protection in archives
- License compliance checking with SBOM generation
- Protection against zip bombs and decompression attacks
Developer Experience Improvements
- Assertion Generation - Automatically generate test assertions based on your use cases, saving time in test creation
- SQLite WAL Mode - Improved performance and reliability for local evaluations with better concurrent access
- Enhanced Token Tracking - Per-provider token usage statistics help you monitor costs across different LLM providers
- Evaluation Time Limits - New
PROMPTFOO_MAX_EVAL_TIME_MSenvironment variable prevents runaway evaluations from consuming excessive resources - Custom Headers Support - Added support for custom headers in Azure and Google Gemini providers for enterprise authentication needs
- WebSocket Header Support - Enhanced WebSocket providers with custom header capabilities
Red Teaming
Enterprise Features
Advanced Testing Capabilities for Teams
Generic attacks often miss system-specific vulnerabilities. We've added powerful features for organizations that need sophisticated AI security testing to create targeted tests that match your actual security risks:
-
Target Discovery Agent - Automatically analyzes your AI system to understand its capabilities and craft more effective, targeted attacks
-
Adaptive Red Team Strategies - Define complex multi-turn attack strategies with enhanced capabilities for targeted testing
-
Grader Customization - Fine-tune evaluation criteria at the plugin level with concrete examples for more accurate assessments
-
Cloud-based Plugin Severity Overrides - Enterprise users can centrally manage and customize severity levels for red team plugins across their organization
Plugins
Comprehensive Safety Testing for High-Stakes Domains
Different industries face unique AI risks. We've introduced specialized plugins for industries where AI errors have serious consequences, ensuring you're testing for the failures that matter most in your domain:
Medical Safety Testing
Medical Plugins detect critical healthcare risks:
- Hallucination - Fabricated medical studies or drug interactions
- Prioritization Errors - Dangerous mistakes in triage scenarios
- Anchoring Bias - Fixation on initial symptoms while ignoring critical information
- Sycophancy - Agreeing with incorrect medical assumptions from users
Financial Risk Detection
Financial Plugins identify domain-specific vulnerabilities:
- Calculation Errors - Mistakes in financial computations
- Compliance Violations - Regulatory breaches in advice or operations
- Data Leakage - Exposure of confidential financial information
- Hallucination - Fabricated market data or investment advice
Bias Detection Suite
Biased AI systems can perpetuate discrimination at scale. Our new comprehensive bias detection tests ensure your AI treats all users fairly and respectfully across:
- Age - Ageism in hiring, healthcare, or service recommendations
- Disability - Unfair assumptions about capabilities
- Gender - Role stereotypes and differential treatment
- Race - Ethnic stereotypes and discriminatory patterns
Enterprise-Grade Datasets
- Aegis Dataset - NVIDIA's 26,000+ manually annotated interactions across 13 safety categories for comprehensive content safety testing
New Red Team Capabilities
Intent Plugin Enhancements
The Intent (Custom Prompts) plugin now supports JSON file uploads with nested arrays for multi-step attack sequences. The enhanced UI makes it easier to manage complex test scenarios.
Enhanced HTTP Provider Support
Red team tests now include automatic token estimation for HTTP providers, helping you track costs even with custom API integrations.
System Prompt Override Testing
A new System Prompt Override plugin tests whether your LLM deployment is vulnerable to system instruction manipulation—a critical security flaw that could disable safety features.
Strategies
Smarter Multi-Turn Attack Techniques
Real attacks rarely succeed in a single message. We've enhanced our attack strategies to better simulate how bad actors actually try to manipulate AI systems through extended, adaptive conversations:
-
Enhanced GOAT and Crescendo - Now include intelligent agents that can:
- Navigate multi-step verification processes
- Respond to intermediate prompts like "confirm your account"
- Handle conditional logic in conversations
- Adapt strategies based on system responses
-
Emoji Encoding Strategy - New obfuscation technique using emoji to bypass content filters