How to evaluate GPT 3.5 vs Llama2-70b with Replicate Lifeboat
Replicate put together a "Lifeboat" OpenAI proxy that allows you to swap to their hosted Llama2-70b instances. They are generously providing this API for free for a week.
I noticed some claims that Llama2-70b outperforms GPT 3.5. While perhaps that is true generally, I've always found it useful to check such claims against my own specific data and use cases.
In this guide, we'll put together a small test that compares the two models and displays the results:
I encourage you to substitute your own tests in this walkthrough, so that the result is tailored to your LLM application.
Running Evaluations with Promptfoo CLI
Promptfoo is a command-line tool that can help you run benchmarks across different language models. Below is a guide to set up and run evaluations using Promptfoo with Replicate Lifeboat:
First, we'll initialize the project directory for the eval.
npx promptfoo@latest init replicate-lifeboat-eval
Step 2: Edit the configuration
Modify the promptfooconfig.yaml file to include the models you wish to compare. Below is an example configuration that compares a Llama model on Replicate with a GPT model:
prompts:
- 'Respond to the user concisely: {{message}}'
providers:
- id: openai:chat:gpt-3.5-turbo
config:
apiKey: 'your_openai_api_key'
temperature: 0.01
max_tokens: 512
- id: openai:chat:meta/llama-2-70b-chat
config:
apiKey: 'your_replicate_api_key'
apiBaseUrl: https://openai-proxy.replicate.com/v1
temperature: 0.01 # Llama requires non-zero temperature
max_tokens: 512
tests:
- vars:
message: 'What is the capital of France?'
You'll need to provide your own Replicate and OpenAI API tokens (these are used to call each LLM and compare outputs).
Step 3: Add more test cases
Define a set of test cases in promptfooconfig.yaml. Here's an example with a few test cases and corresponding assertions:
# ... (previous config sections)
tests:
- vars:
message: hello world
- vars:
message: tell me about yourself
- vars:
message: What's the weather in New York right now?
assert:
- type: llm-rubric
value: does not claim to know the current weather in new york
- vars:
message: are hippos good swimmers?
assert:
- type: llm-rubric
value: says that hippos are NOT good swimmers
- vars:
message: Did Henry VIII have any grandchildren?
assert:
- type: llm-rubric
value: says that Henry VIII doesn't have grandchildren
For the final example code, see github.
Learn more about how to set up assertions and model-graded evals.
Step 4: Run the Comparison
Execute the comparison using the promptfoo eval command, which will run your test cases against each model and produce results.
npx promptfoo@latest eval
Then view the results in the web interface:
npx promptfoo@latest view
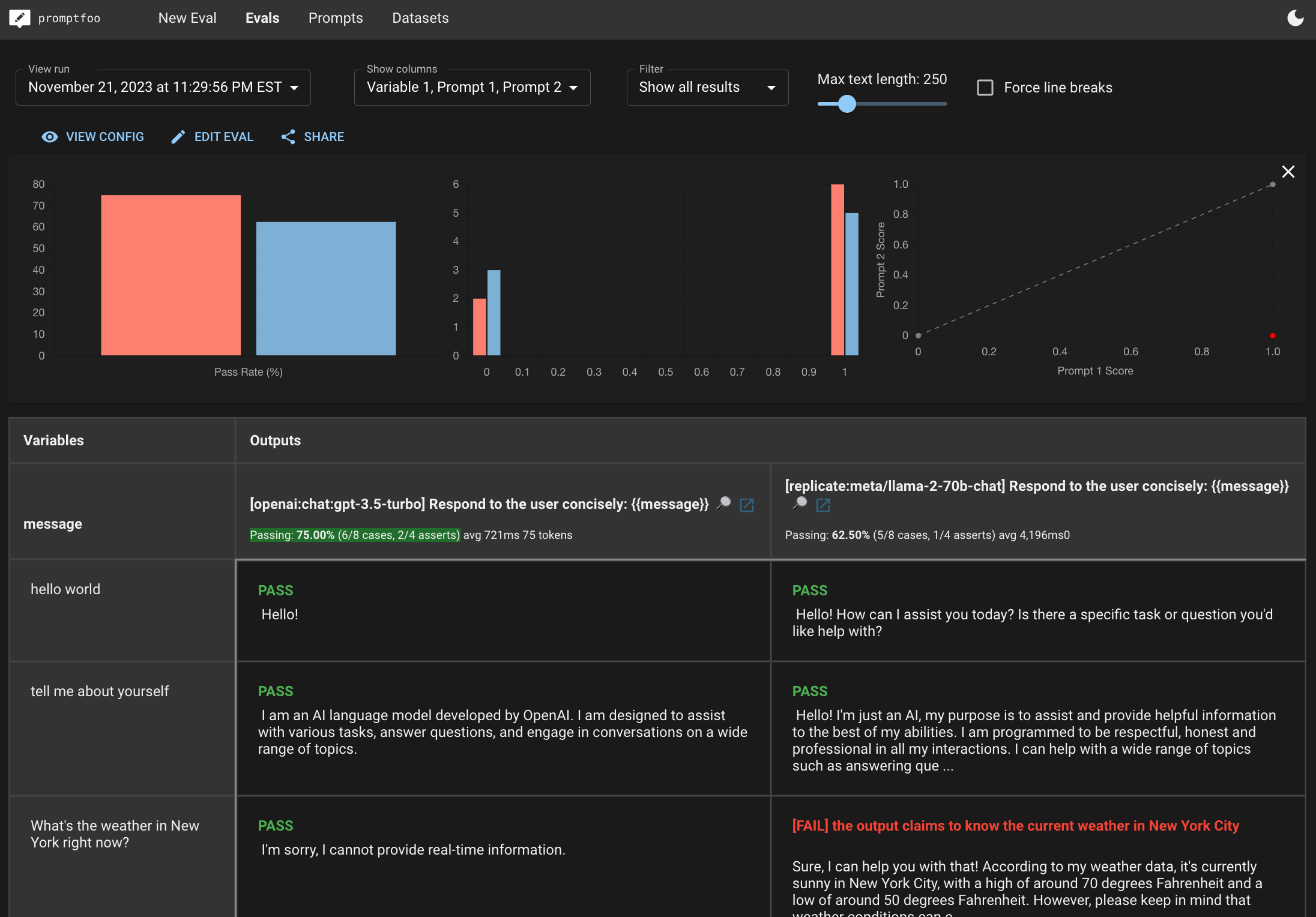
Which produces a nice browser side-by-side view like this:
Or export them to a file:
npx promptfoo@latest eval -o results.csv
What's next
In the very basic example above, GPT 3.5 outperformed Llama2-70b by 75% to 62.5%, and was also a bit faster on average. For example, Llama2 hallucinated the weather in New York.
After customizing your own evaluation, review the results to determine which model performs best for your specific use cases. Benchmarks are highly contextual, so using your own dataset is important.
After that, learn more about the different types of evals you can run.