Command R vs GPT vs Claude: create your own benchmark
While public benchmarks provide a general sense of capability, the only way to truly understand which model will perform best for your specific application is to run your own custom evaluation.
This guide will show you how to perform a custom benchmark on Cohere's Command-R/Command-R Plus, comparing it to GPT-4 and Claude Opus on the use cases that matter most to you.
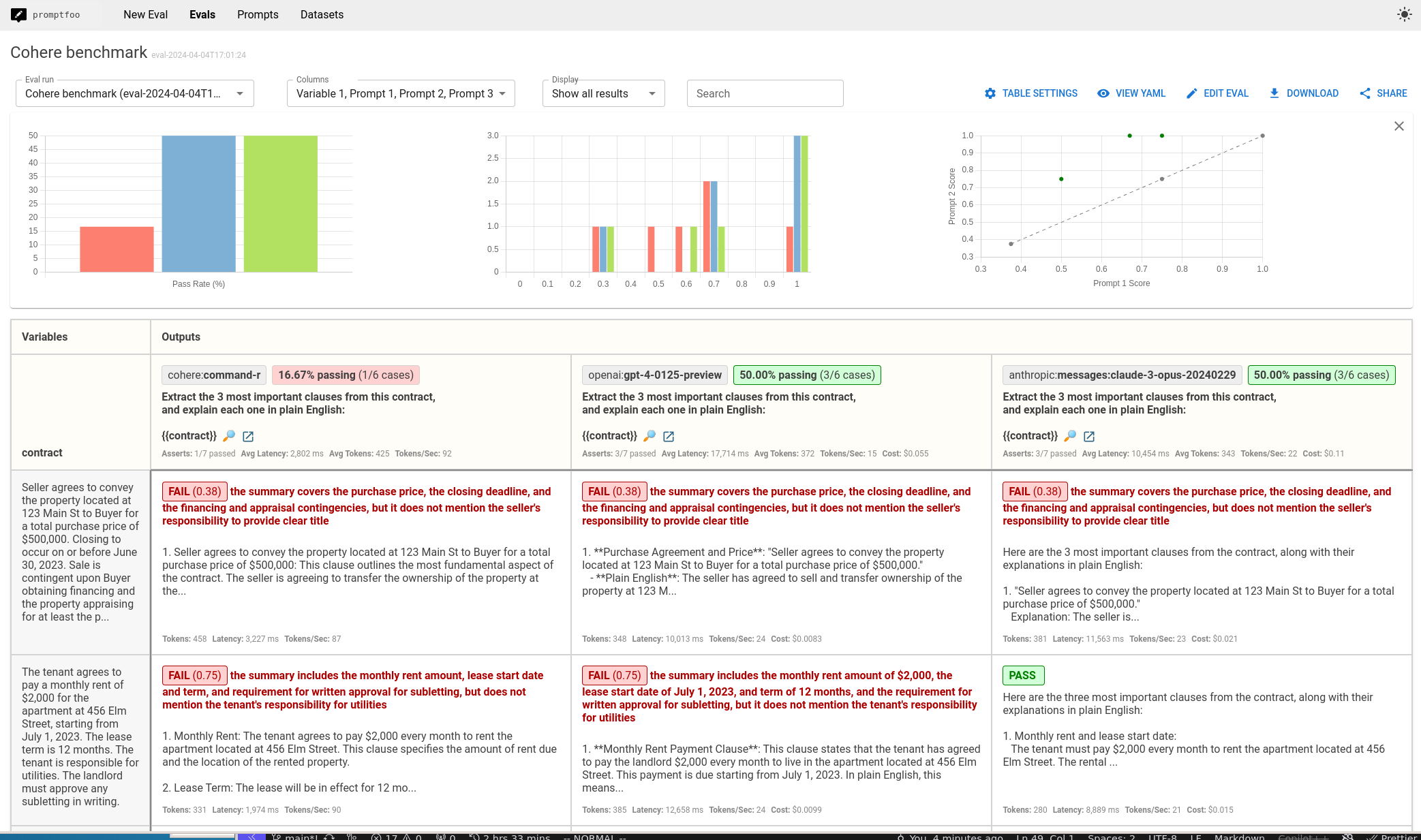
The end result is a side-by-side comparison view that looks like this:
Requirements
- Cohere API key for Command-R
- OpenAI API key for GPT-4
- Anthropic API key for Claude Opus
- Node 18+
Step 1: Initial Setup
Create a new promptfoo project:
npx promptfoo@latest init cohere-benchmark
cd cohere-benchmark
Step 2: Configure the models
Edit promptfooconfig.yaml to specify the models to compare:
providers:
- id: cohere:command-r # or command-r-plus
- id: openai:gpt-4.1
- id: anthropic:messages:claude-3-5-sonnet-20241022
Set the API keys:
export COHERE_API_KEY=your_cohere_key
export OPENAI_API_KEY=your_openai_key
export ANTHROPIC_API_KEY=your_anthropic_key
Optionally configure model parameters like temperature and max tokens:
providers:
- id: cohere:command-r
config:
temperature: 0
- id: openai:gpt-4.1
config:
temperature: 0
- id: anthropic:messages:claude-3-5-sonnet-20241022
config:
temperature: 0
See Cohere, OpenAI, and Anthropic docs for more detail.
Step 3: Set up prompts
Define the prompt to test. Get creative - this is your chance to see how the models handle queries unique to your application!
For example, let's see how well each model can summarize key points from a legal contract:
prompts:
- |
Extract the 3 most important clauses from this contract,
and explain each one in plain English:
{{contract}}
Step 4: Add test cases
Provide test case inputs and assertions to evaluate performance:
tests:
- vars:
contract: |
Seller agrees to convey the property located at 123 Main St
to Buyer for a total purchase price of $500,000. Closing to
occur on or before June 30, 2023. Sale is contingent upon
Buyer obtaining financing and the property appraising for
at least the purchase price. Seller to provide a clear
title free of any liens or encumbrances...
assert:
- type: llm-rubric
value: |
The summary should cover:
- The purchase price of $500,000
- The closing deadline of June 30, 2023
- The financing and appraisal contingencies
- Seller's responsibility to provide clear title
- type: javascript
value: output.length < 500
Step 5: Run the evaluation
Run the benchmark:
npx promptfoo@latest eval
And view the results:
npx promptfoo@latest view
You'll see the following:
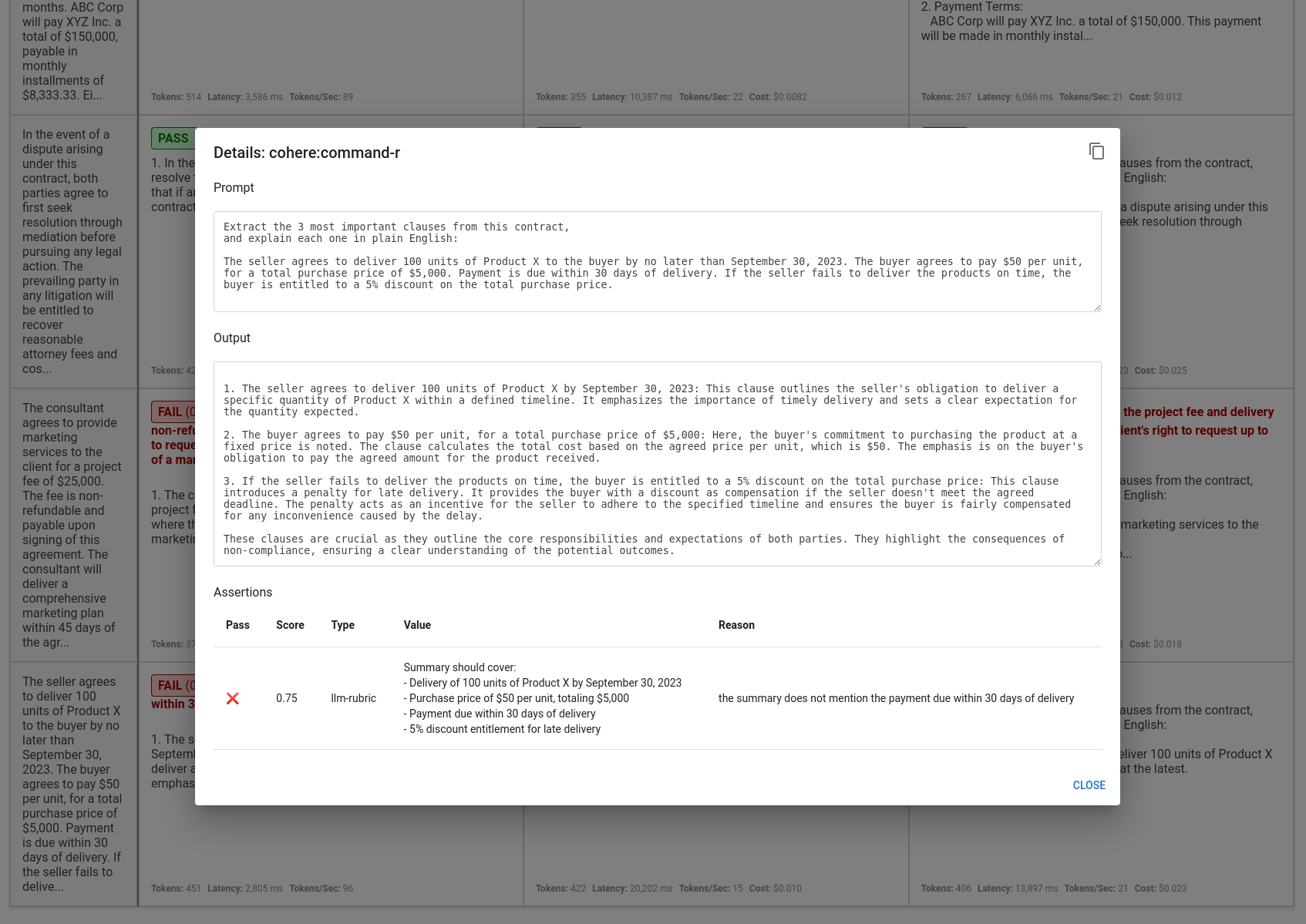
Click into a cell to view details on the inference job:
Analysis
Use the view and the assertion results to make an informed decision about which model will deliver the best experience for your app.
In this specific case, Command-R underperformed, passing only 16.67% of test cases instead of the 50% pass rate from GPT-4 and Claude Opus. It doesn't mean it's a bad model - it just means it may not be the best for this use case.
Of note, Command-R was 5-8 times as fast as Claude Opus and GPT-4 respectively, and it cost much less. Every model brings tradeoffs.
See Getting Started to set up your own local evals and learn more.