Claude 3.7 vs GPT-4.1: Benchmark on Your Own Data
When evaluating the performance of LLMs, generic benchmarks will only get you so far. This is especially the case for Claude vs GPT, as there are many split evaluations (subjective and objective) on their efficacy.
You should test these models on tasks that are relevant to your specific use case, rather than relying solely on public benchmarks.
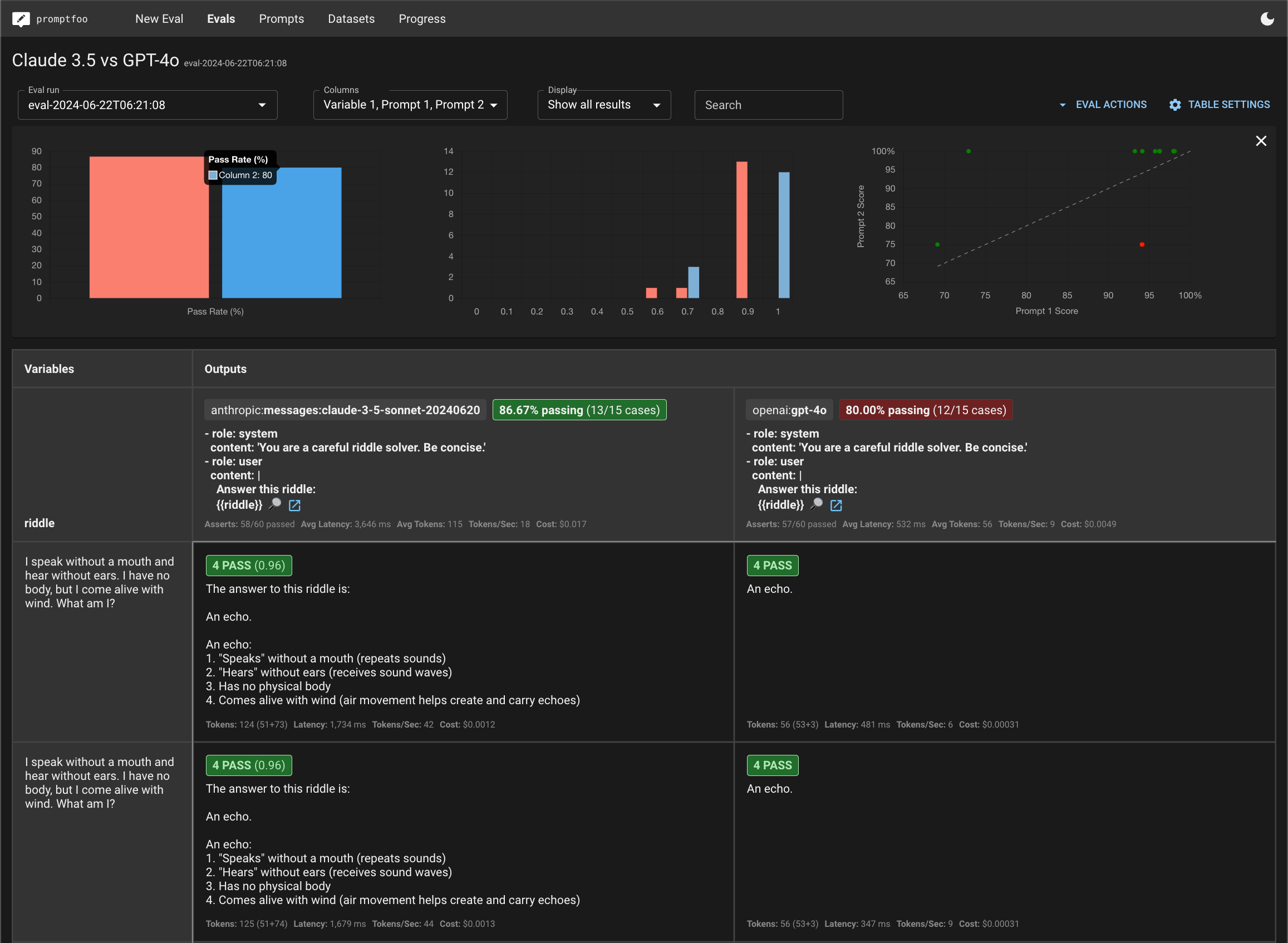
This guide will walk you through setting up a comparison between Anthropic's Claude 3.7 and OpenAI's GPT-4.1 using promptfoo. The end result is a side-by-side evaluation of how these models perform on custom tasks:
Prerequisites
Before getting started, make sure you have:
- The
promptfooCLI installed (installation instructions) - API keys for Anthropic (
ANTHROPIC_API_KEY) and OpenAI (OPENAI_API_KEY)
Step 1: Set Up Your Evaluation
Create a new directory for your comparison project:
npx promptfoo@latest init claude3.7-vs-gpt4o
cd claude3.7-vs-gpt4o
Open the generated promptfooconfig.yaml file. This is where you'll configure the models to test, the prompts to use, and the test cases to run.
Configure the Models
Specify the Claude 3.7 and GPT-4.1 model IDs under providers:
providers:
- anthropic:messages:claude-3-7-sonnet-20250219
- openai:chat:gpt-4.1
You can optionally set parameters like temperature and max tokens for each model:
providers:
- id: anthropic:messages:claude-3-7-sonnet-20250219
config:
temperature: 0.3
max_tokens: 1024
- id: openai:chat:gpt-4.1
config:
temperature: 0.3
max_tokens: 1024
Define Your Prompts
Next, define the prompt(s) you want to test the models on. For this example, we'll just use a simple prompt:
prompts:
- 'Answer this riddle: {{riddle}}
If desired, you can use a prompt template defined in a separate prompt.yaml or prompt.json file. This makes it easier to set the system message, etc:
prompts:
- file://prompt.yaml
The contents of prompt.yaml:
- role: system
content: 'You are a careful riddle solver. Be concise.'
- role: user
content: |
Answer this riddle:
{{riddle}}
The {{riddle}} placeholder will be populated by test case variables.
Step 2: Create Test Cases
Now it's time to create a set of test cases that represent the types of queries your application needs to handle.
The key is to focus your analysis on the cases that matter most for your application. Think about the edge cases and specific competencies that you need in an LLM.
In this example, we'll use a few riddles to test the models' reasoning and language understanding capabilities:
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
- type: icontains
value: echo
- vars:
riddle: "You see a boat filled with people. It has not sunk, but when you look again you don't see a single person on the boat. Why?"
assert:
- type: llm-rubric
value: explains that the people are below deck or they are all in a relationship
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
assert:
- type: icontains
value: darkness
# ... more test cases
The assert blocks allow you to automatically check the model outputs for expected content. This is useful for tracking performance over time as you refine your prompts.
promptfoo supports a very wide variety of assertions, ranging from basic asserts to model-graded to assertions specialized for RAG applications.
Step 3: Run the Evaluation
With your configuration complete, you can kick off the evaluation:
npx promptfoo@latest eval
This will run each test case against both Claude 3.7 and GPT-4.1 and record the results.
To view the results, start up the promptfoo viewer:
npx promptfoo@latest view
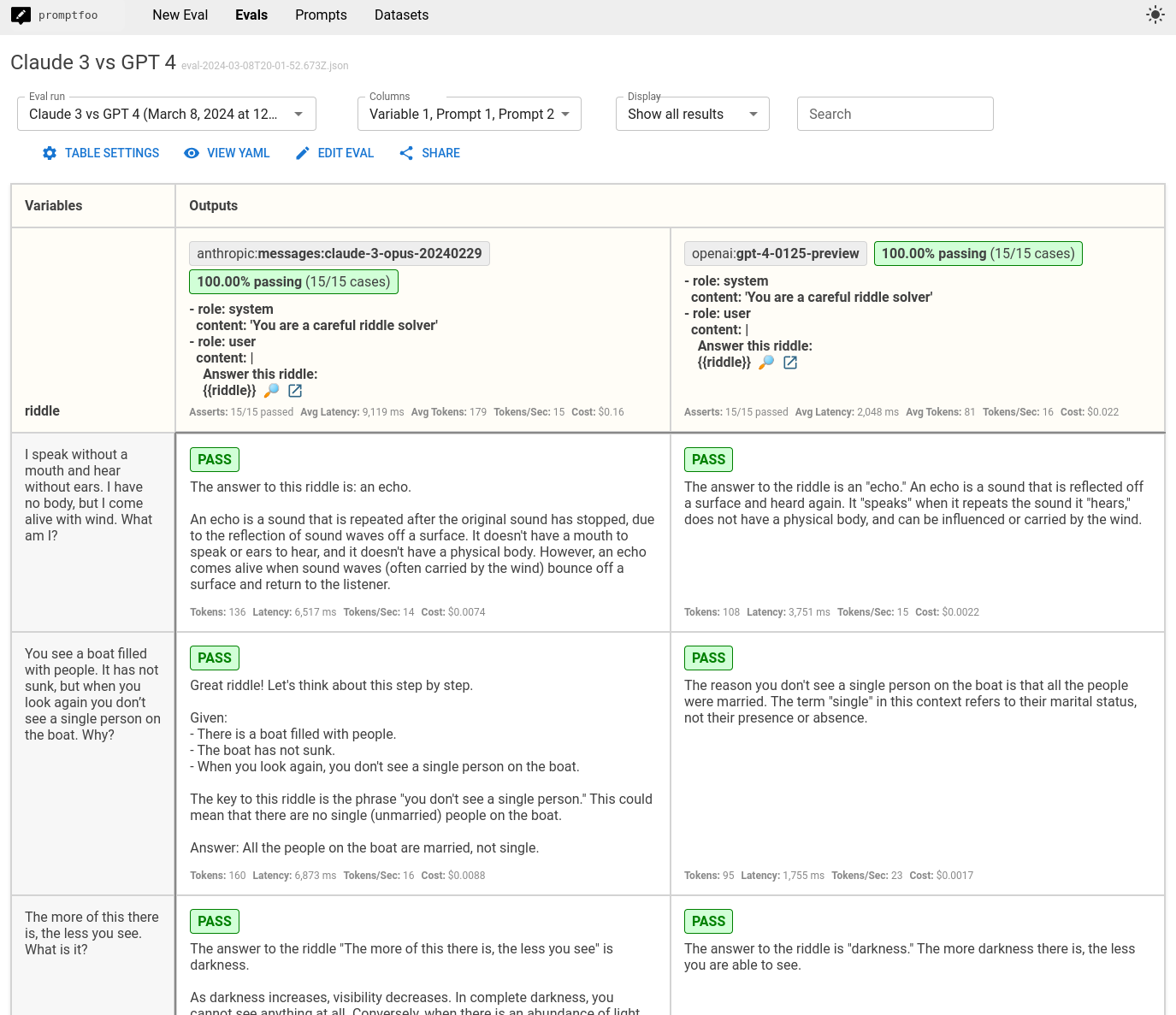
This will display a comparison view showing how Claude 3.7 and GPT-4.1 performed on each test case:
You can also output the raw results data to a file:
npx promptfoo@latest eval -o results.json
Step 4: Analyze the Results
With the evaluation complete, it's time to dig into the results and see how the models compared on your test cases.
Some key things to look for:
- Which model had a higher overall pass rate on the test assertions? In this case, both models did equally well in terms of getting the answer, which is great - these riddles often trip up less powerful models like GPT 3.5 and Claude 2.
- Were there specific test cases where one model significantly outperformed the other?
- How did the models compare on other output quality metrics.
- Consider model properties like speed and cost in addition to quality.
Here are a few observations from our example riddle test set:
- GPT 4o's responses tended to be shorter, while Claude 3.7 often includes extra commentary
- GPT 4o was about 7x faster
- GPT 4o was about 3x cheaper
Adding assertions for things we care about
Based on the above observations, let's add the following assertions to all tests in this eval:
- Latency must be under 2000 ms
- Cost must be under $0.0025
- Sliding scale Javascript function that penalizes long responses
defaultTest:
assert:
- type: cost
threshold: 0.0025
- type: latency
threshold: 2000
- type: javascript
value: 'output.length <= 100 ? 1 : output.length > 1000 ? 0 : 1 - (output.length - 100) / 900'
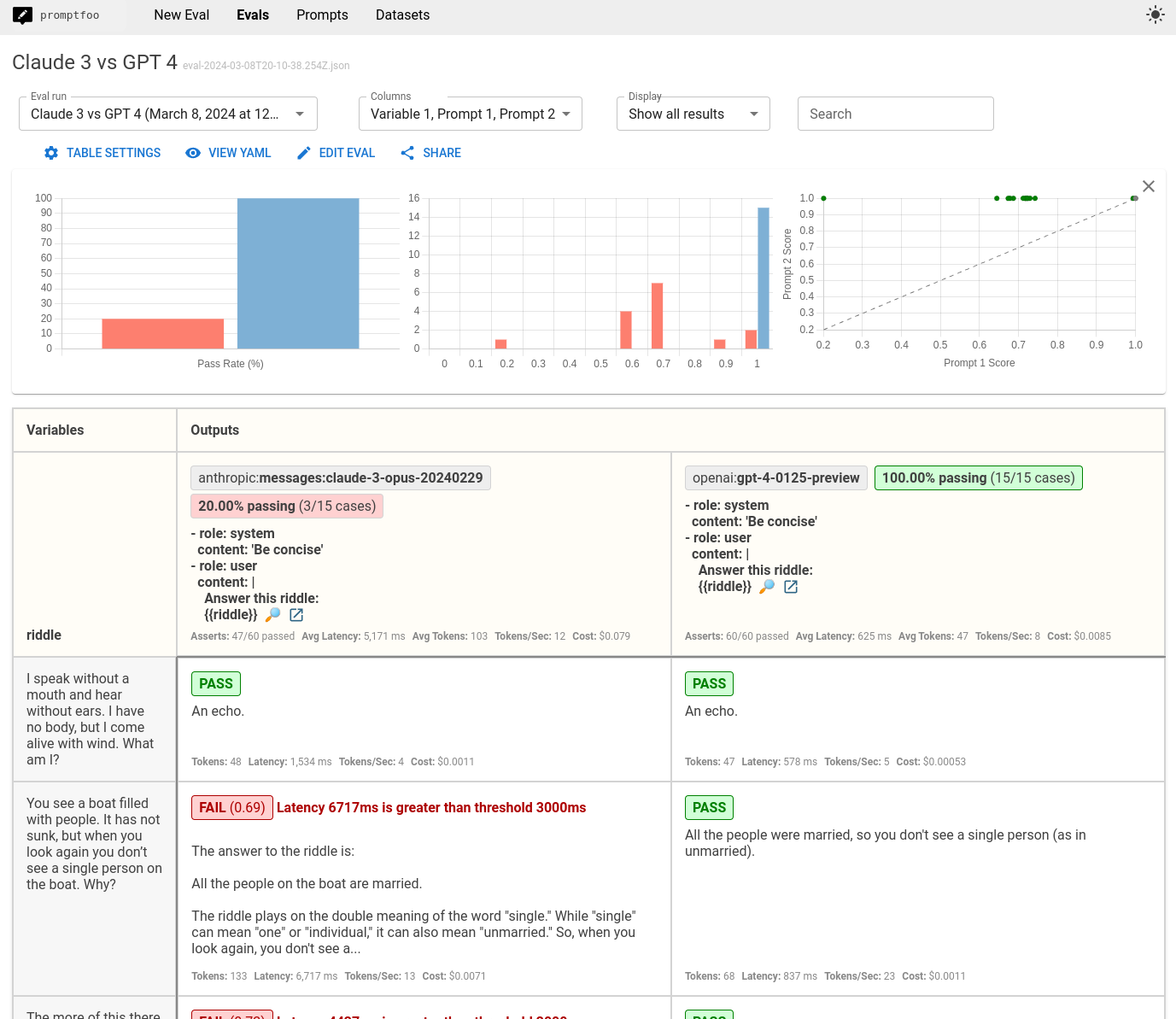
We're also going to update the system prompt to say, "Be concise".
The result is that Claude 3.7 frequently fails our latency requirements:
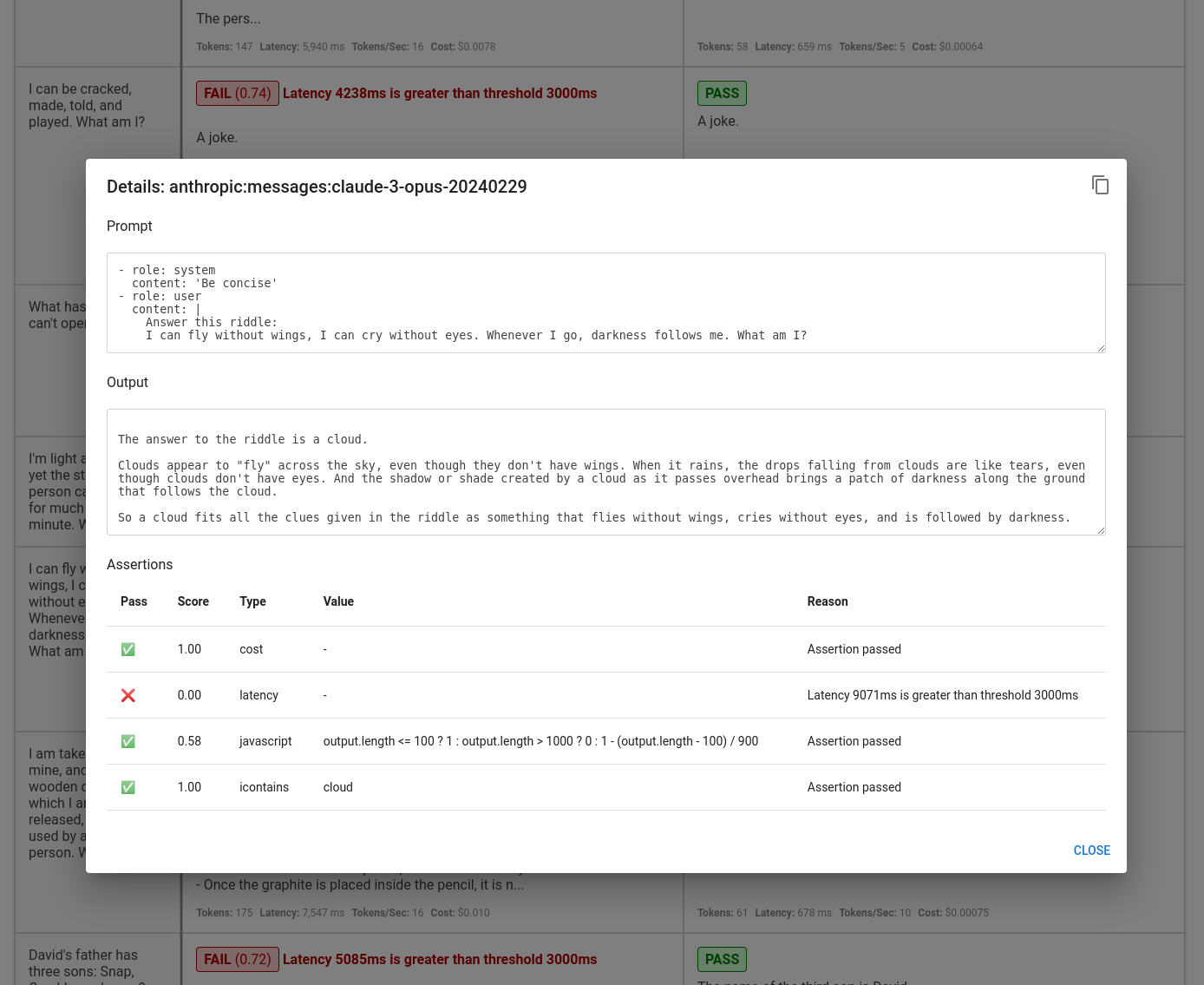
Clicking into a specific test case shows the individual test results:
Of course, our requirements are different from yours. You should customize these values to suit your use case.
Conclusion
By running this type of targeted evaluation, you can gain valuable insights into how Claude 3.7 and GPT-4.1 are likely to perform on your application's real-world data and tasks.
promptfoo makes it easy to set up a repeatable evaluation pipeline so you can test models as they evolve and measure the impact of model and prompt changes.
The end goal: choose the best foundation model for your use case with empirical data.
To learn more about promptfoo, check out the getting started guide and configuration reference.