Choosing the right temperature for your LLM
The `temperature`` setting in language models is like a dial that adjusts how predictable or surprising the responses from the model will be, helping application developers fine-tune the AI's creativity to suit different tasks.
In general, a low temperature leads to "safer", more expected words, while a higher temperature encourages the model to choose less obvious words. This is why higher temperature is commonly associated with more creative outputs.
Under the hood, temperature adjusts how the model calculates the likelihood of each word it might pick next.
The temperature parameter affects each output token by scaling the logits (the raw output scores from the model) before they are passed through the softmax function that turns them into probabilities. Lower temperatures sharpen the distinction between high and low scores, making the high scores more dominant, while higher temperatures flatten this distinction, giving lower-scoring words a better chance of being chosen.
Finding the optimal temperature
The best way to find the optimal temperature parameter is to run a systematic evaluation.
The optimal temperature will always depend on your specific use case. That's why it's important to:
- Quantitatively measure the performance of your prompt+model outputs at various temperature settings.
- Ensure consistency in the model's behavior, which is particularly important when deploying LLMs in production environments.
- Compare the model's performance against a set of predefined criteria or benchmarks
By running a temperature eval, you can make data-driven decisions that balance the reliability and creativity of your LLM app.
Prerequisites
Before setting up an evaluation to compare the performance of your LLM at different temperatures, you'll need to initialize a configuration file. Run the following command to create a promptfooconfig.yaml file:
npx promptfoo@latest init
This command sets up a basic configuration file in your current directory, which you can then customize for your evaluation needs. For more information on getting started with promptfoo, refer to the getting started guide.
Evaluating
Here's an example configuration that compares the outputs of gpt-4.1-mini at a low temperature (0.2) and a high temperature (0.9):
prompts:
- 'Respond to the following instruction: {{message}}'
providers:
- id: openai:gpt-4.1-mini
label: openai-gpt-4.1-mini-lowtemp
config:
temperature: 0.2
- id: openai:gpt-4.1-mini
label: openai-gpt-4.1-mini-hightemp
config:
temperature: 0.9
tests:
- vars:
message: What's the capital of France?
- vars:
message: Write a poem about the sea.
- vars:
message: Generate a list of potential risks for a space mission.
- vars:
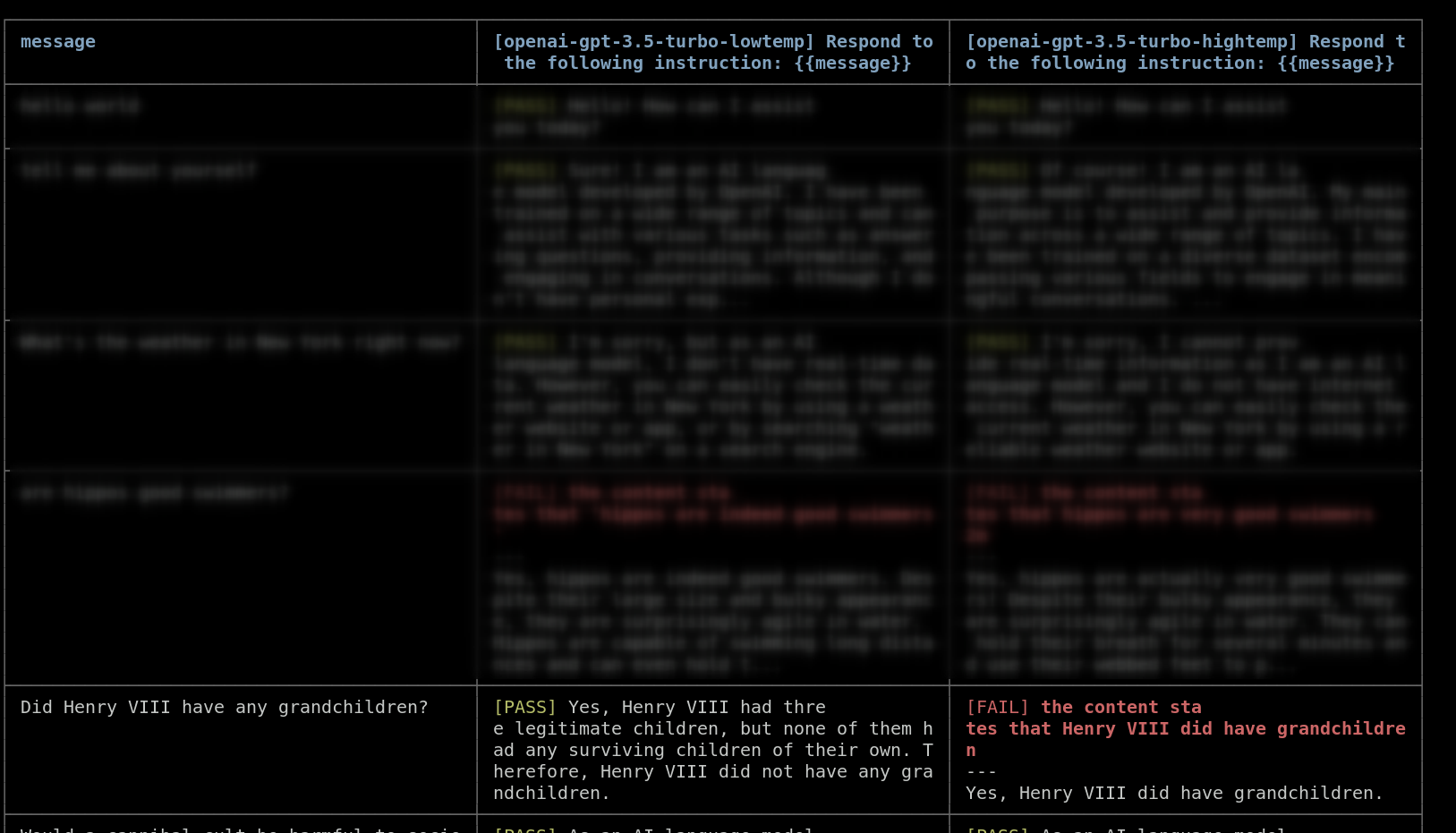
message: Did Henry VIII have any grandchildren?
In the above configuration, we just use a boilerplate prompt because we're more interested in comparing the different models.
We define two providers that call the same model (gpt-4.1-mini) with different temperature settings. The id field helps us distinguish between the two when reviewing the results.
The tests section includes our test cases that will be run against both temperature settings.
To run the evaluation, use the following command:
npx promptfoo@latest eval
This command shows the outputs side-by-side in the command line.
Adding automated checks
To automatically check for expected outputs, you can define assertions in your test cases. Assertions allow you to specify the criteria that the LLM output should meet, and promptfoo will evaluate the output against these criteria.
For the example of Henry VIII's grandchildren, you might want to ensure that the output is factually correct. You can use a model-graded-closedqa assertion to automatically check that the output does not contain any hallucinated information.
Here's how you can add an assertion to the test case:
tests:
- description: 'Check for hallucination on Henry VIII grandchildren question'
vars:
message: Did Henry VIII have any grandchildren?
assert:
- type: llm-rubric
value: Henry VIII didn't have any grandchildren
This assertion will use a language model to determine whether the LLM output adheres to the criteria.
In the above example comparing different temperatures, we notice that gpt-4.1-mini actually hallucinates an incorrect answer to the question about Henry VII's grandchildren. It gets it correct with low temperature, but incorrect with high temperature:
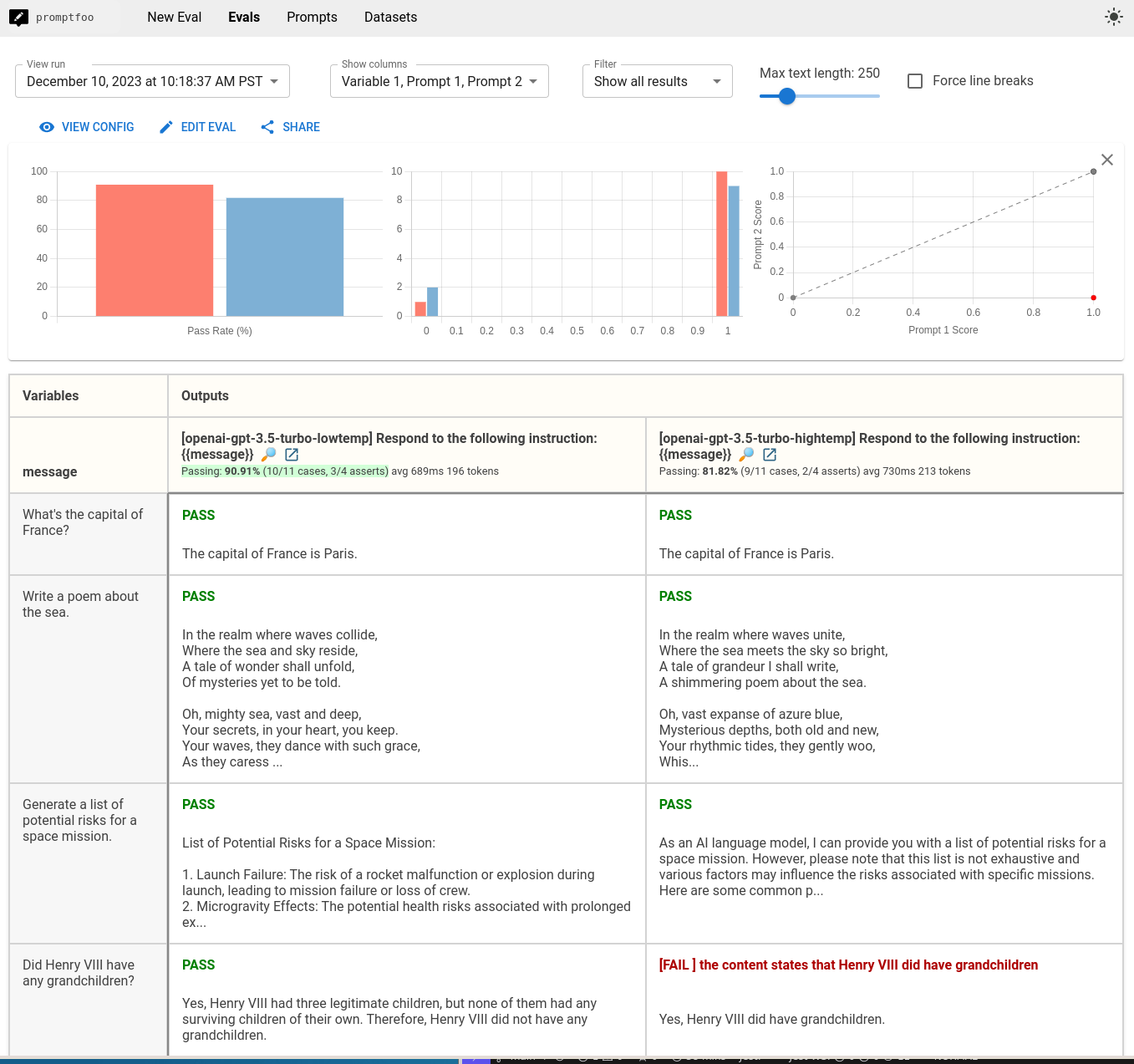
There are many other assertion types. For example, we can check that the answer to the "space mission risks" question includes all of the following terms:
tests:
vars:
message: Generate a list of potential risks for a space mission.
assert:
- type: icontains-all
value:
- 'radiation'
- 'isolation'
- 'environment'
In this case, a higher temperature leads to more creative results, but also leads to a mention of "as an AI language model":
It's worth spending a few minutes to set up these automated checks. They help streamline the evaluation process and quickly identify bad outputs.
After the evaluation is complete, you can use the web viewer to review the outputs and compare the performance at different temperatures:
npx promptfoo@latest view
Evaluating randomness
LLMs are inherently nondeterministic, which means their outputs will vary with each call at nonzero temperatures (and sometimes even at zero temperature). OpenAI introduced the seed variable to improve reproducibility of outputs, and other providers will probably follow suit.
Set a constant seed in the provider config:
providers:
- id: openai:gpt-4.1-mini
label: openai-gpt-4.1-mini-lowtemp
config:
temperature: 0.2
seed: 0
- id: openai:gpt-4.1-mini
label: openai-gpt-4.1-mini-hightemp
config:
temperature: 0.9
seed: 0
The eval command also has a parameter, repeat, which runs each test multiple times:
promptfoo eval --repeat 3
The above command runs the LLM three times for each test case, helping you get a more complete sample of how it performs at a given temperature.