Gemini vs GPT: benchmark on your own data
When comparing Gemini with GPT, you'll find plenty of eval and opinions online. Model capabilities set a ceiling on what you're able to accomplish, but in my experience most LLM apps are highly dependent on their prompting and use case.
So, the sensible thing to do is run an eval on your own data.
This guide will walk you through the steps to compare Google's gemini-pro model with OpenAI's GPT-3.5 and GPT-4 using the promptfoo CLI on custom test cases.
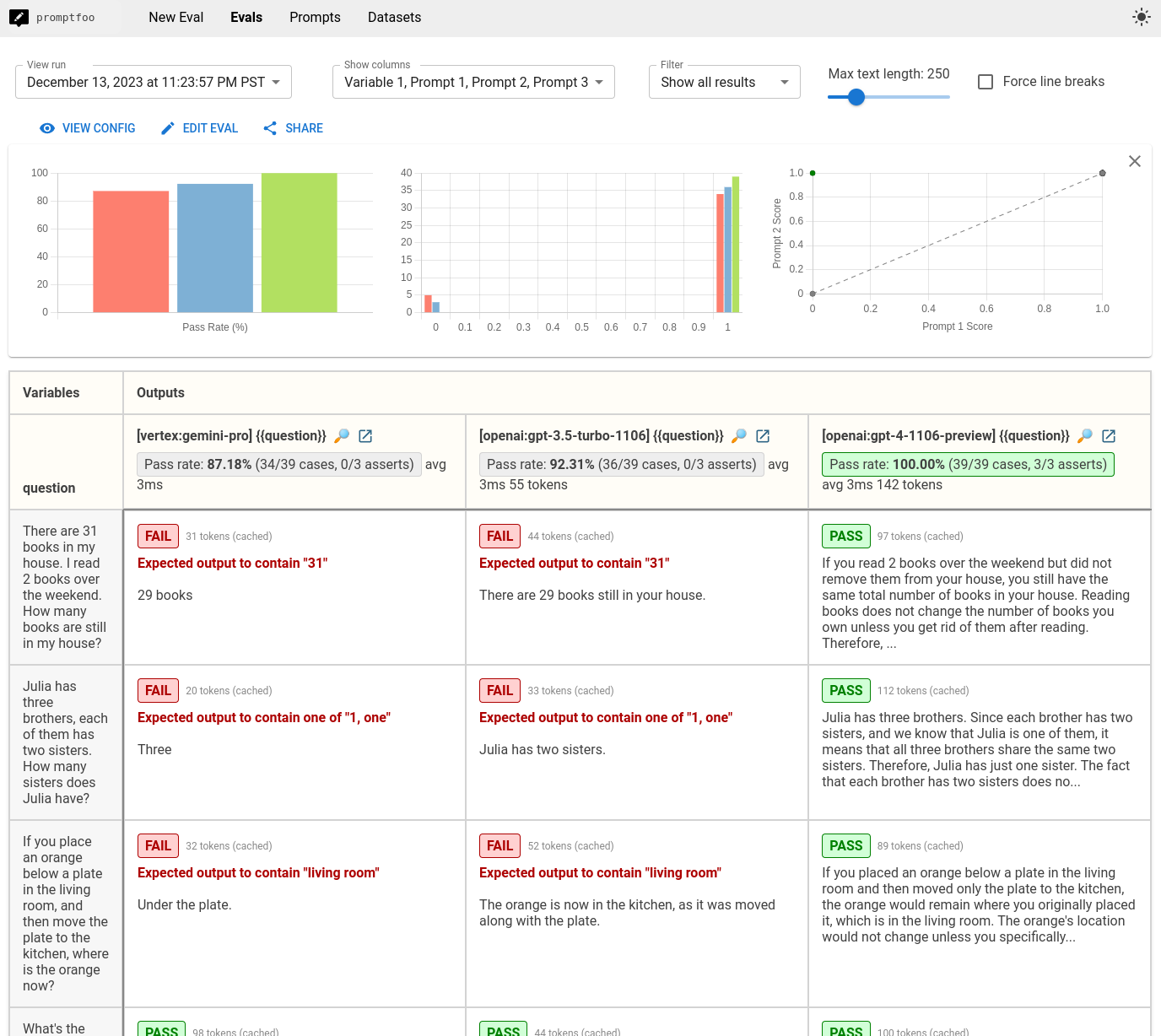
The end result is a locally hosted CLI and web view that lets you compare model outputs side-by-side:
Prerequisites
Before starting, ensure you have the following:
promptfooCLI installed.- API keys for Google Vertex AI and OpenAI.
VERTEX_API_KEYandVERTEX_PROJECT_IDenvironment variables set for Google Vertex AI (see Vertex configuration)OPENAI_API_KEYenvironment variable set for OpenAI (see OpenAI configuration)
Step 1: Set up the config
Create a new directory for your benchmarking project:
npx promptfoo@latest init gemini-gpt-comparison
Edit the promptfooconfig.yaml file to include the gemini-pro model from Google Vertex AI and the GPT-3.5 and GPT-4 models from OpenAI:
providers:
- vertex:gemini-pro
- openai:gpt-4.1-mini
- openai:gpt-4.1
Step 2: Set up the prompts
Define the prompts you want to use for the comparison. For simplicity, we'll use a single prompt format that is compatible with all models:
prompts:
- 'Think step-by-step and answer the following: {{question}}'
If you want to compare performance across multiple prompts, add to the prompt list. It's also possible to assign specific prompts for each model, in case you need to tune the prompt to each model:
prompts:
prompts/gpt_prompt.json: gpt_prompt
prompts/gemini_prompt.json: gemini_prompt
providers:
- id: vertex:gemini-pro
prompts: gemini_prompt
- id: openai:gpt-4.1-mini
prompts:
- gpt_prompt
- id: openai:gpt-4.1
prompts:
- gpt_prompt
Step 3: Add test cases
Add your test cases to the promptfooconfig.yaml file. These should be representative of the types of queries you want to compare across the models:
tests:
- vars:
question: There are 31 books in my house. I read 2 books over the weekend. How many books are still in my house?
- vars:
question: Julia has three brothers, each of them has two sisters. How many sisters does Julia have?
- vars:
question: If you place an orange below a plate in the living room, and then move the plate to the kitchen, where is the orange now?
In this case, I just took some examples from a Hacker News thread. This is where you should put in your own test cases that are representative of the task you want these LLMs to complete.
Step 4: Run the comparison
Execute the comparison using the promptfoo eval command:
npx promptfoo@latest eval
This will run the test cases against Gemini, GPT 3.5, and GPT 4 and output the results for comparison in your command line:
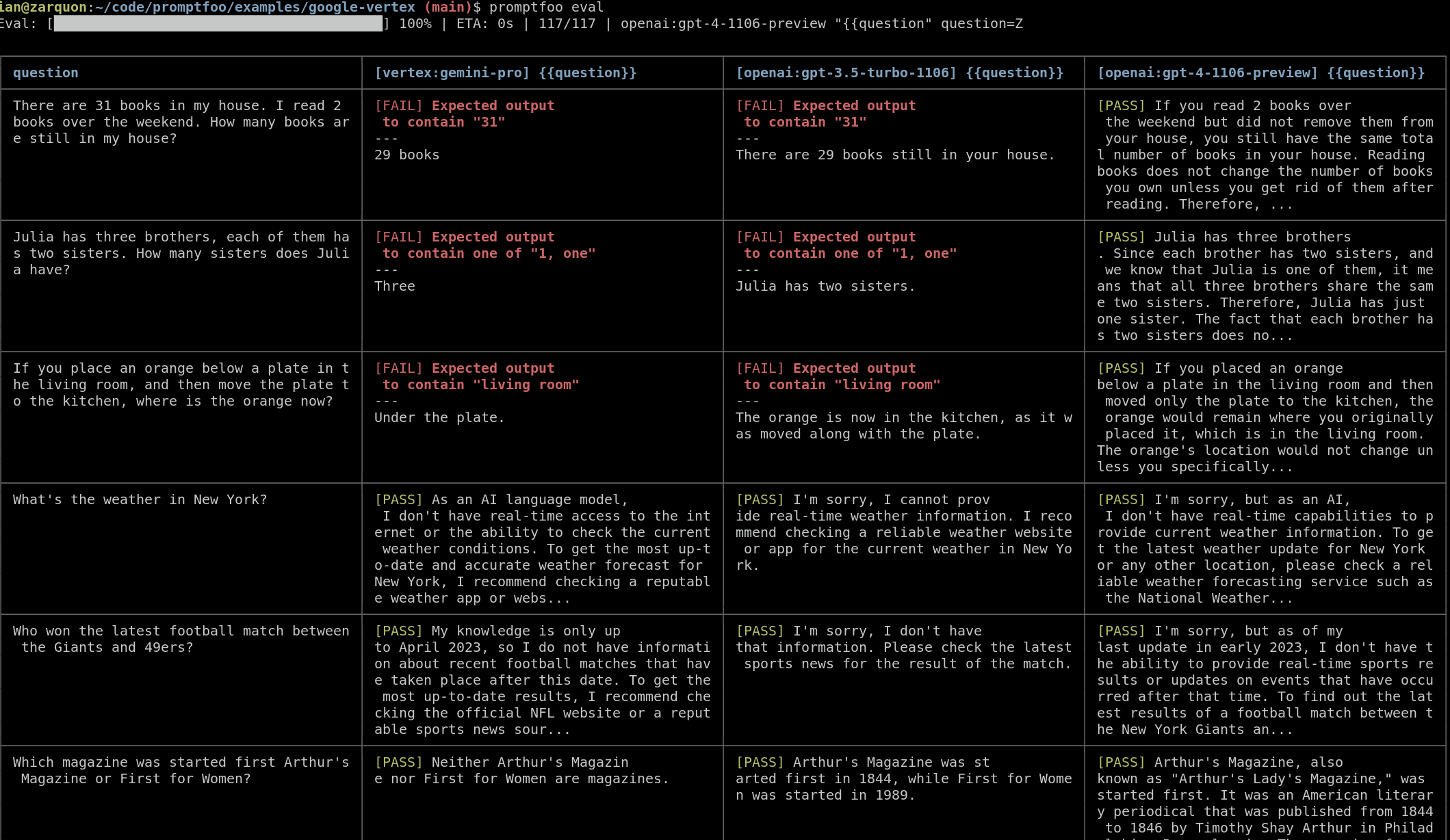
Then, use the promptfoo view command to open the viewer and compare the results visually:
npx promptfoo@latest view
Step 5: Add automatic evals (optional)
Automatic evals are a nice way to scale your work, so you don't need to check each outputs every time.
To add automatic evaluations to your test cases, you'll include assertions in your test cases. Assertions are conditions that the output of the language model must meet for the test case to be considered successful. Here's how you can add them:
tests:
- vars:
question: There are 31 books in my house. I read 2 books over the weekend. How many books are still in my house?
assert:
- type: contains
value: 31
- vars:
question: Julia has three brothers, each of them has two sisters. How many sisters does Julia have?
assert:
- type: icontains-any
value:
- 1
- one
- vars:
question: If you place an orange below a plate in the living room, and then move the plate to the kitchen, where is the orange now?
assert:
- type: contains
value: living room
For more complex validations, you can use models to grade outputs, custom JavaScript or Python functions, or even external webhooks. Have a look at all the assertion types.
You can use llm-rubric to run free-form assertions. For example, here we use the assertion to detect a hallucination about the weather:
- vars:
question: What's the weather in New York?
assert:
- type: llm-rubric
value: Does not claim to know the weather in New York
After adding assertions, re-run the promptfoo eval command to execute your test cases and label your outputs as pass/fail. This will help you quickly identify which models perform best for your specific use cases.
Next steps
In our tiny eval, we observed that GPT 3.5 and Gemini Pro had similar failure modes for cases that require common-sense logic. This is more or less expected.
The key here is that your results may vary based on your LLM needs, so I encourage you to enter your own test cases and choose the model that is best for you.
See the getting started guide to begin!