Testing LLM chains
Prompt chaining is a common pattern used to perform more complex reasoning with LLMs. It's used by libraries like LangChain, and OpenAI has released built-in support via OpenAI functions.
A "chain" is defined by a list of LLM prompts that are executed sequentially (and sometimes conditionally). The output of each LLM call is parsed/manipulated/executed, and then the result is fed into the next prompt.
This page explains how to test an LLM chain. At a high level, you have these options:
-
Break the chain into separate calls, and test those. This is useful if your testing strategy is closer to unit tests, rather than end to end tests.
-
Test the full end-to-end chain, with a single input and single output. This is useful if you only care about the end result, and are not interested in how the LLM chain got there.
Unit testing LLM chains
As mentioned above, the easiest way to test is one prompt at a time. This can be done pretty easily with a basic promptfoo configuration.
Create a promptfooconfig.yaml for the first step of your chain. After configuring test cases for that step, create a new set of test cases for step 2 and so on.
End-to-end testing for LLM chains
Using a script provider
To test your chained LLMs, provide a script that takes a prompt input and outputs the result of the chain. This approach is language-agnostic.
In this example, we'll test LangChain's LLM Math plugin by creating a script that takes a prompt and produces an output:
# langchain_example.py
import sys
import os
from langchain_openai import OpenAI
from langchain.chains.llm_math.base import LLMMathChain
llm = OpenAI(
temperature=0,
api_key=os.getenv('OPENAI_API_KEY')
)
llm_math = LLMMathChain.from_llm(llm=llm)
prompt = sys.argv[1]
print(llm_math.run(prompt))
This script is set up so that we can run it like this:
python langchain_example.py "What is 2+2?"
Now, let's configure promptfoo to run this LangChain script with a bunch of test cases:
prompts: file://prompt.txt
providers:
- openai:chat:gpt-5.4
- exec:python langchain_example.py
tests:
- vars:
question: What is the cube root of 389017?
- vars:
question: If you have 101101 in binary, what number does it represent in base 10?
- vars:
question: What is the natural logarithm (ln) of 89234?
- vars:
question: If a geometric series has a first term of 3125 and a common ratio of 0.008, what is the sum of the first 20 terms?
- vars:
question: A number in base 7 is 3526. What is this number in base 10?
- vars:
question: If a complex number is represented as 3 + 4i, what is its magnitude?
- vars:
question: What is the fourth root of 1296?
For an in-depth look at configuration, see the guide. Note the following:
- prompts:
prompt.txtis just a file that contains{{question}}, since we're passing the question directly through to the provider. - providers: We list GPT-5.4 in order to compare its outputs with LangChain's LLMMathChain. We also use the
execdirective to make promptfoo run the Python script in its eval.
In this example, the end result is a side-by-side comparison of GPT-5.4 vs. LangChain math performance:
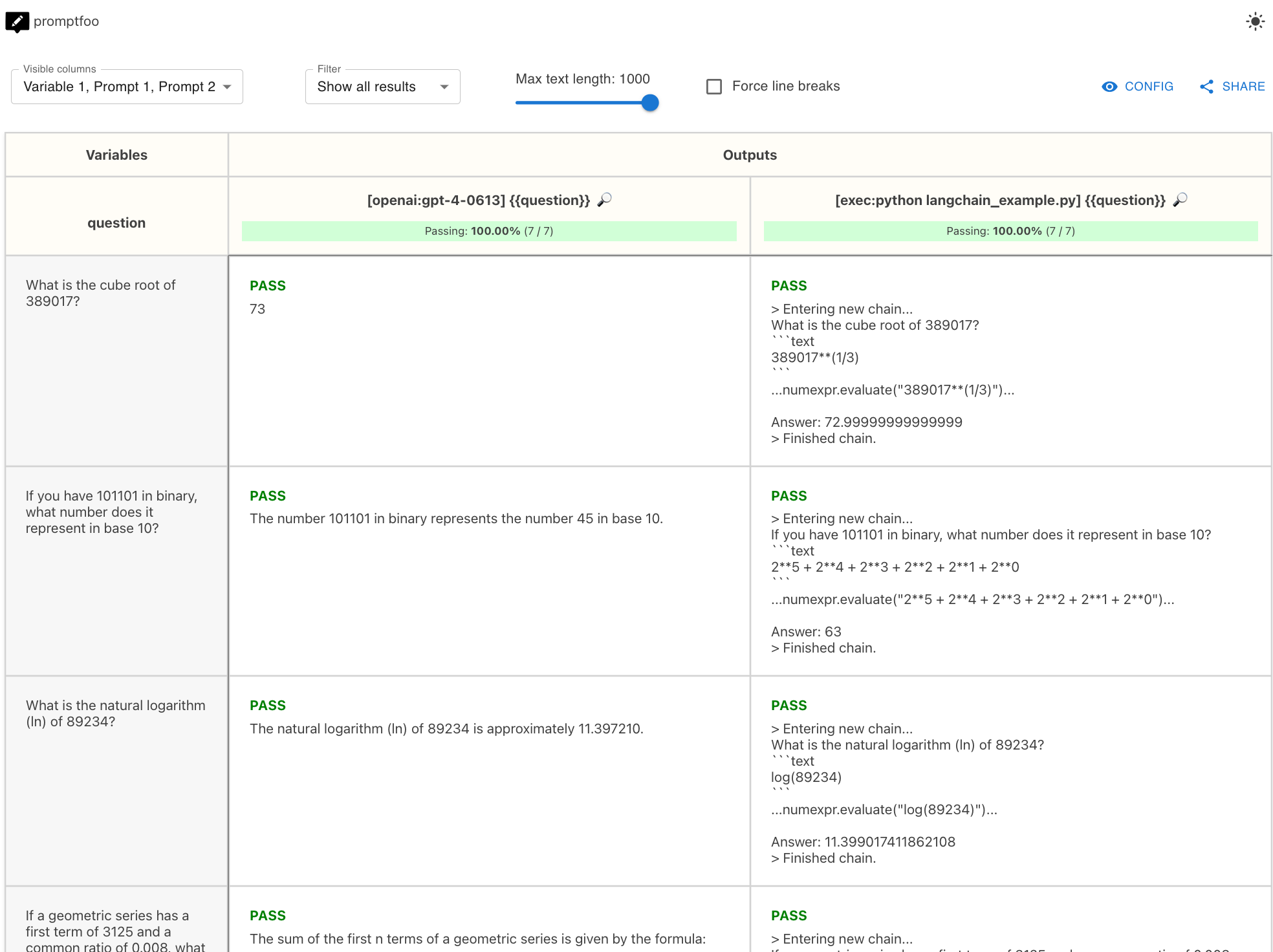
View the full example on Github.
Using a custom provider
For finer-grained control, use a custom provider.
A custom provider is a short Javascript file that defines a callApi function. This function can invoke your chain. Even if your chain is not implemented in Javascript, you can write a custom provider that shells out to Python.
In the example below, we set up a custom provider that runs a Python script with a prompt as the argument. The output of the Python script is the final result of the chain.
const { spawn } = require('child_process');
class ChainProvider {
id() {
return 'my-python-chain';
}
async callApi(prompt, context) {
return new Promise((resolve, reject) => {
const pythonProcess = spawn('python', ['./path_to_your_python_chain.py', prompt]);
let output = '';
pythonProcess.stdout.on('data', (data) => {
output += data.toString();
});
pythonProcess.stderr.on('data', (data) => {
reject(data.toString());
});
pythonProcess.on('close', (code) => {
if (code !== 0) {
reject(`python script exited with code ${code}`);
} else {
resolve({
output,
});
}
});
});
}
}
module.exports = ChainProvider;
Note that you can always write the logic directly in Javascript if you're comfortable with the language.
Now, we can set up a promptfoo config pointing to chainProvider.js:
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- './chainProvider.js'
tests:
- vars:
language: French
input: Hello world
- vars:
language: German
input: How's it going?
promptfoo will pass the full constructed prompts to chainProvider.js and the Python script, with variables substituted. In this case, the script will be called # prompts * # test cases = 2 * 2 = 4 times.
Using this approach, you can test your LLM chain end-to-end, view results in the web view, set up continuous testing, and so on.
Retrieval-augmented generation (RAG)
For more detail on testing RAG pipelines, see RAG evaluations.
Other tips
To reference the outputs of previous test cases, use the built-in _conversation variable.