OpenAI vs Azure: How to benchmark
Whether you use GPT through the OpenAI or Azure APIs, the results are pretty similar. But there are some key differences:
- Speed of inference
- Frequency of model updates (Azure tends to move more slowly here) and therefore variation between models
- Variation in performance between Azure regions
- Cost
- Ease of integration
- Compliance with data regulations
This guide will walk you through a systematic approach to comparing these models using the promptfoo CLI tool.
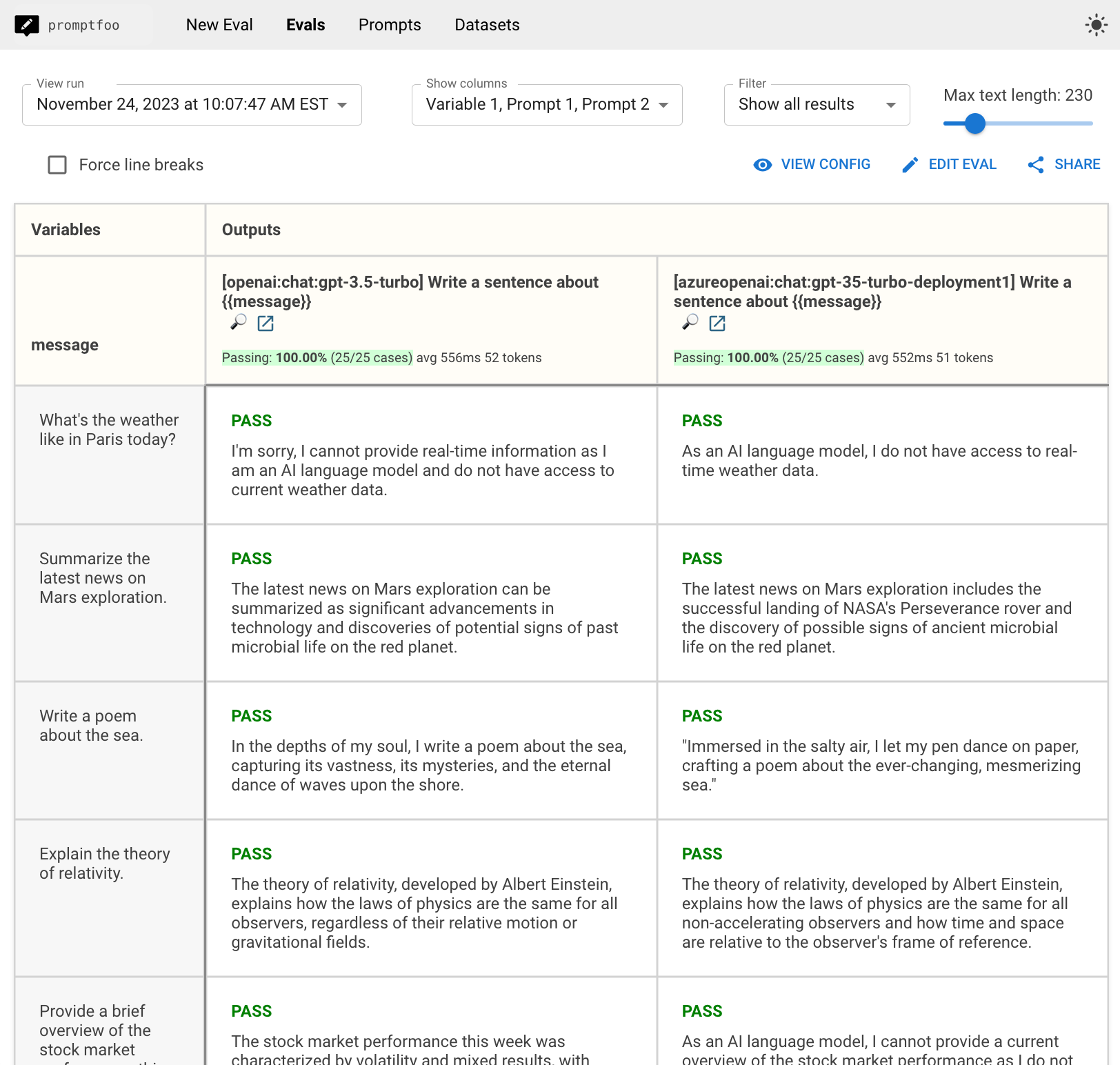
The end result will be a side-by-side comparison view that looks like this, which includes timing information and outputs.
Prerequisites
Before we get started, you need the following:
- An API key for OpenAI and Azure OpenAI services.
- Install
promptfoo.
Additionally, make sure you have the following environment variables set:
OPENAI_API_KEY='...'
AZURE_API_KEY='...'
Step 1: Set up the models
Initialize the example project:
npx promptfoo@latest init --example openai-azure-comparison
cd openai-azure-comparison
Open the promptfooconfig.yaml and configure both OpenAI and Azure OpenAI as providers. In this example, we'll compare the same model on both services.
providers:
- id: openai:chat:gpt-5-mini
- id: azure:chat:my-gpt-5-mini-deployment
config:
apiHost: myazurehost.openai.azure.com
Make sure to replace the above with the actual host and deployment name for your Azure OpenAI instances.
Step 2: Create prompts and test cases
Define the prompts and test cases you want to use for the comparison. In this case, we're just going to test a single prompt, but we'll add a few test cases:
prompts:
- 'Answer the following concisely: {{message}}'
tests:
- vars:
message: "What's the weather like in Paris today?"
- vars:
message: 'Summarize the latest news on Mars exploration.'
- vars:
message: 'Write a poem about the sea.'
Step 3: Run the comparison
Execute the comparison using the promptfoo eval command:
npx promptfoo@latest eval --no-cache
This will run the test cases against both models and output the results.
We've added the --no-cache directive because we care about timings (in order to see which provider is faster), so we don't want any cached results.
Step 4: Review results and analyze
After running the eval command, promptfoo will generate a report with the responses from both models.
Run promptfoo view to open the viewer:
Inference speed
In this particular test run over 25 examples, it shows that there is negligible difference in speed of inference - OpenAI and Azure take 556 ms and 552 ms on average, respectively.
Once you set up your own test cases, you can compare the results to ensure that response time and latency on your Azure deployment is consistent.
Output accuracy & consistency
Interestingly, the outputs may differ between providers even with identical configurations.
The comparison view makes it easy to ensure that the accuracy and relevance of the responses are consistent.
Next steps
Once you've set up some test cases, you can automatically test the outputs to ensure that they conform to your requirements. To learn more about automating this setup, go to Test Assertions.