Choosing the best GPT model: benchmark on your own data
This guide will walk you through how to compare OpenAI's GPT-5.2 and GPT-5-mini, top contenders for the most powerful and effective GPT models. This testing framework will give you the chance to test the models' reasoning capabilities, cost, and latency.
New model releases often score well on benchmarks. But generic benchmarks are for generic use cases. If you're building an LLM app, you should evaluate these models on your own data and make an informed decision based on your specific needs.
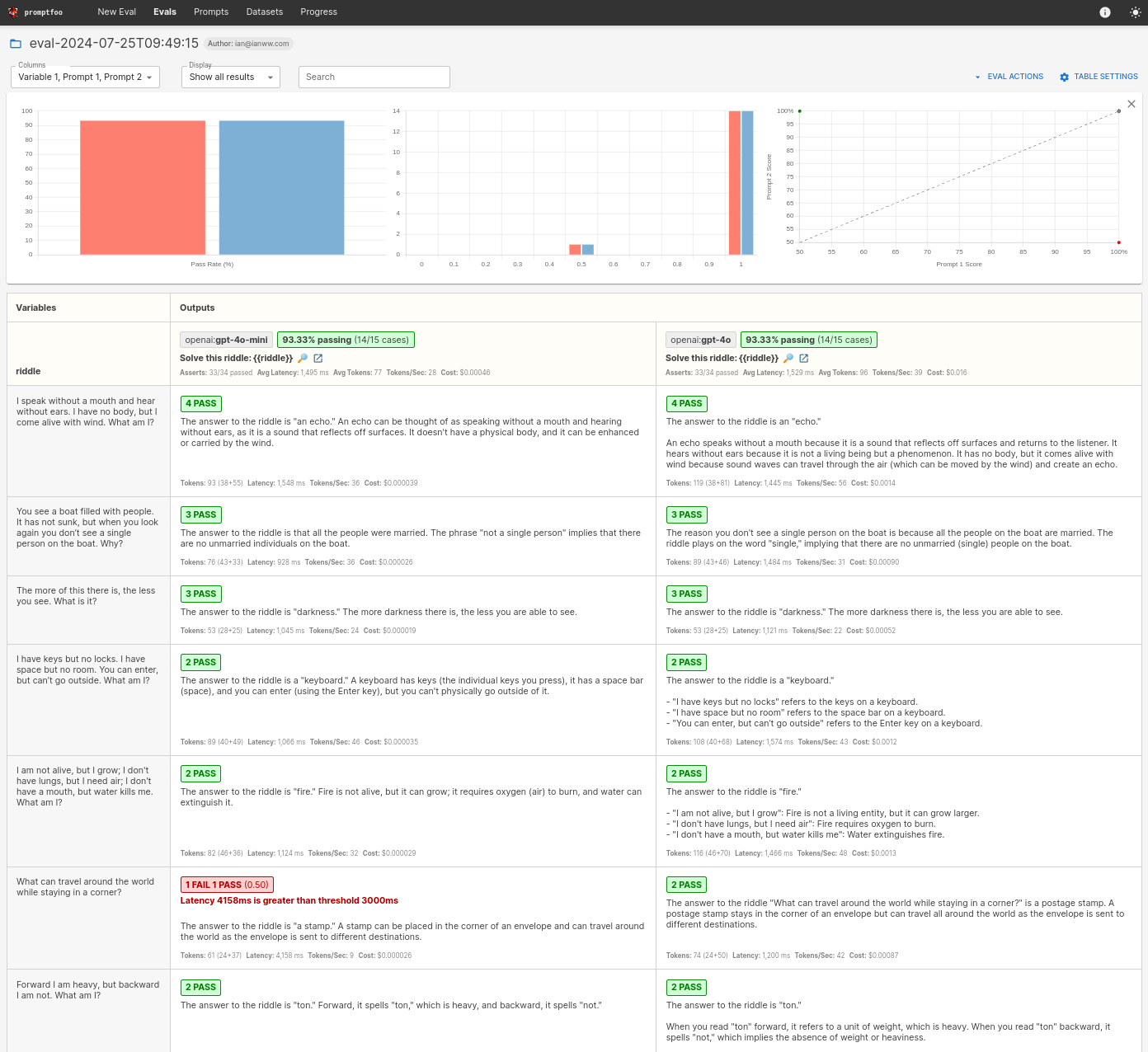
The end result will be a side-by-side comparison that looks like this:
Prerequisites
To start, make sure you have:
- promptfoo CLI installed. If not, refer to the installation guide.
- An active OpenAI API key set as the
OPENAI_API_KEYenvironment variable. See OpenAI configuration for details.
Step 1: Setup
Create a dedicated directory for your comparison project:
mkdir gpt-comparison
cd gpt-comparison
Create a promptfooconfig.yaml with both models:
providers:
- openai:gpt-5-mini
- openai:gpt-5.2
Step 2: Crafting the prompts
For our comparison, we'll use a simple prompt:
prompts:
- 'Solve this riddle: {{riddle}}'
Feel free to add multiple prompts and tailor to your use case.
Step 3: Create test cases
Above, we have a {{riddle}} placeholder variable. Each test case runs the prompts with a different riddle:
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
- vars:
riddle: 'You see a boat filled with people. It has not sunk, but when you look again you don’t see a single person on the boat. Why?'
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
Step 4: Run the comparison
Execute the comparison with the following command:
npx promptfoo@latest eval
This will process the riddles against both GPT-5-mini and GPT-5.2, providing you with side-by-side results in your command line interface:
npx promptfoo@latest view
Step 5: Automatic evaluation
To streamline the evaluation process, you can add various types of assertions to your test cases. Assertions verify if the model's output meets certain criteria, marking the test as pass or fail accordingly.
In this case, we're especially interested in cost and latency assertions given the tradeoffs between the two models:
tests:
- vars:
riddle: 'I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?'
assert:
# Make sure the LLM output contains this word
- type: contains
value: echo
# Inference should always cost less than this (USD)
- type: cost
threshold: 0.001
# Inference should always be faster than this (milliseconds)
- type: latency
threshold: 5000
# Use model-graded assertions to enforce free-form instructions
- type: llm-rubric
value: Do not apologize
- vars:
riddle: 'You see a boat filled with people. It has not sunk, but when you look again you don’t see a single person on the boat. Why?'
assert:
- type: cost
threshold: 0.002
- type: latency
threshold: 3000
- type: llm-rubric
value: explains that the people are below deck
- vars:
riddle: 'The more of this there is, the less you see. What is it?'
assert:
- type: contains
value: darkness
- type: cost
threshold: 0.0015
- type: latency
threshold: 4000
After setting up your assertions, rerun the promptfoo eval command. This automated process helps quickly determine which model best fits your reasoning task requirements.
For more info on available assertion types, see assertions & metrics.
Cleanup
Finally, we'll use defaultTest to clean things up a bit and apply global latency and cost requirements. Here's the final eval config:
providers:
- openai:gpt-5-mini
- openai:gpt-5.2
prompts:
- 'Solve this riddle: {{riddle}}'
defaultTest:
assert:
# Inference should always cost less than this (USD)
- type: cost
threshold: 0.001
# Inference should always be faster than this (milliseconds)
- type: latency
threshold: 3000
tests:
- vars:
riddle: "I speak without a mouth and hear without ears. I have no body, but I come alive with wind. What am I?"
assert:
- type: contains
value: echo
- vars:
riddle: "You see a boat filled with people. It has not sunk, but when you look again you don’t see a single person on the boat. Why?"
assert:
- type: llm-rubric
value: explains that the people are below deck
- vars:
riddle: "The more of this there is, the less you see. What is it?"
assert:
- type: contains
value: darkness
For more info on setting up the config, see the configuration guide.
Conclusion
In the end, you will see a result like this:
In this particular eval, the models performed very similarly in terms of answers, but it looks like GPT-5.2 exceeded our maximum latency. Notably, GPT-5.2 was more expensive compared to GPT-5-mini.
Of course, this is a limited example test set. The tradeoff between cost, latency, and accuracy is going to be tailored for each application. That's why it's important to run your own eval.
I encourage you to experiment with your own test cases and use this guide as a starting point. To learn more, see Getting Started.