Evaluating RAG pipelines
Retrieval-augmented generation is a method for enriching LLM prompts with relevant data. Typically, the user prompt will be converting into an embedding and matching documents are fetched from a vector store. Then, the LLM is called with the matching documents as part of the prompt.
When designing an evaluation strategy for RAG applications, you should evaluate both steps:
- Document retrieval from the vector store
- LLM output generation
It's important to evaluate these steps separately, because breaking your RAG into multiple steps makes it easier to pinpoint issues.
There are several criteria used to evaluate RAG applications:
- Output-based
- Factuality (also called Correctness): Measures whether the LLM outputs are based on the provided ground truth. See the
factualitymetric. - Answer relevance: Measures how directly the answer addresses the question. See
answer-relevanceorsimilarmetric.
- Factuality (also called Correctness): Measures whether the LLM outputs are based on the provided ground truth. See the
- Context-based
- Context adherence (also called Grounding or Faithfulness): Measures whether LLM outputs are based on the provided context. See
context-adherencemetric. - Context recall: Measures whether the context contains the correct information, compared to a provided ground truth, in order to produce an answer. See
context-recallmetric. - Context relevance: Measures how much of the context is necessary to answer a given query. See
context-relevancemetric.
- Context adherence (also called Grounding or Faithfulness): Measures whether LLM outputs are based on the provided context. See
- Custom metrics: You know your application better than anyone else. Create test cases that focus on things that matter to you (examples include: whether a certain document is cited, whether the response is too long, etc.)
This guide shows how to use promptfoo to evaluate your RAG app. If you're new to Promptfoo, head to Getting Started.
You can also jump to the full RAG example on GitHub.
Evaluating document retrieval
Document retrieval is the first step of a RAG. It is possible to eval the retrieval step in isolation, in order to ensure that you are fetching the best documents.
Suppose we have a simple file retrieve.py, which takes a query and outputs a list of documents and their contents:
import vectorstore
def call_api(query, options, context):
# Fetch relevant documents and join them into a string result.
documents = vectorstore.query(query)
output = "\n".join(f'{doc.name}: {doc.content}' for doc in documents)
result = {
"output": output,
}
# Include error handling and token usage reporting as needed
# if some_error_condition:
# result['error'] = "An error occurred during processing"
#
# if token_usage_calculated:
# result['tokenUsage'] = {"total": token_count, "prompt": prompt_token_count, "completion": completion_token_count}
return result
In practice, your retrieval logic is probably more complicated than the above (e.g. query transformations and fanout). Substitute retrieve.py with a script of your own that prepares the query and talks to your database.
How Promptfoo runs Python retrieval scripts
The file://retrieve.py provider is still run from the normal Node-based Promptfoo CLI. When promptfoo eval reaches that provider, it starts a Python worker, imports retrieve.py, and calls call_api(prompt, options, context) for each test case. The first argument is the rendered prompt, which is the {{ query }} value in this example. You do not need a separate Promptfoo Python package or server.
You do need Python 3 and any libraries your retrieval script imports. If the script uses LangChain, Chroma, a database client, or your own package, install those dependencies into the Python environment that Promptfoo will use:
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
npx promptfoo@latest eval
If you do not want to activate the virtual environment before running Promptfoo, point the provider at the environment's Python executable:
providers:
- id: file://retrieve.py
config:
pythonExecutable: ./.venv/bin/python
You can also set PROMPTFOO_PYTHON=/path/to/python as a global default when the provider does not specify pythonExecutable. See the Python provider docs for more options.
Configuration
We will set up an eval that runs a live document retrieval against the vector database.
In the example below, we're evaluating a RAG chat bot used on a corporate intranet. We add a couple tests to ensure that the expected substrings appear in the document results.
First, create promptfooconfig.yaml. We'll use a placeholder prompt with a single {{ query }} variable. This file instructs promptfoo to run several test cases through the retrieval script.
prompts:
- '{{ query }}'
providers:
- file://retrieve.py
tests:
- vars:
query: What is our reimbursement policy?
assert:
- type: contains-all
value:
- 'reimbursement.md'
- 'hr-policies.html'
- 'Employee Reimbursement Policy'
- vars:
query: How many weeks is maternity leave?
assert:
- type: contains-all
value:
- 'parental-leave.md'
- 'hr-policies.html'
- 'Maternity Leave'
In the above example, the contains-all assertion ensures that the output from retrieve.py contains all the listed substrings. The context-recall assertions use an LLM model to ensure that the retrieval performs well.
You will get the most value out of this eval if you set up your own evaluation test cases. View other assertion types that you can use.
Comparing vector databases
In order to compare multiple vector databases in your evaluation, create retrieval scripts for each one and add them to the providers list:
providers:
- file://retrieve_pinecone.py
- file://retrieve_milvus.py
- file://retrieve_pgvector.py
Running the eval with promptfoo eval will create a comparison view between Pinecone, Milvus, and PGVector:
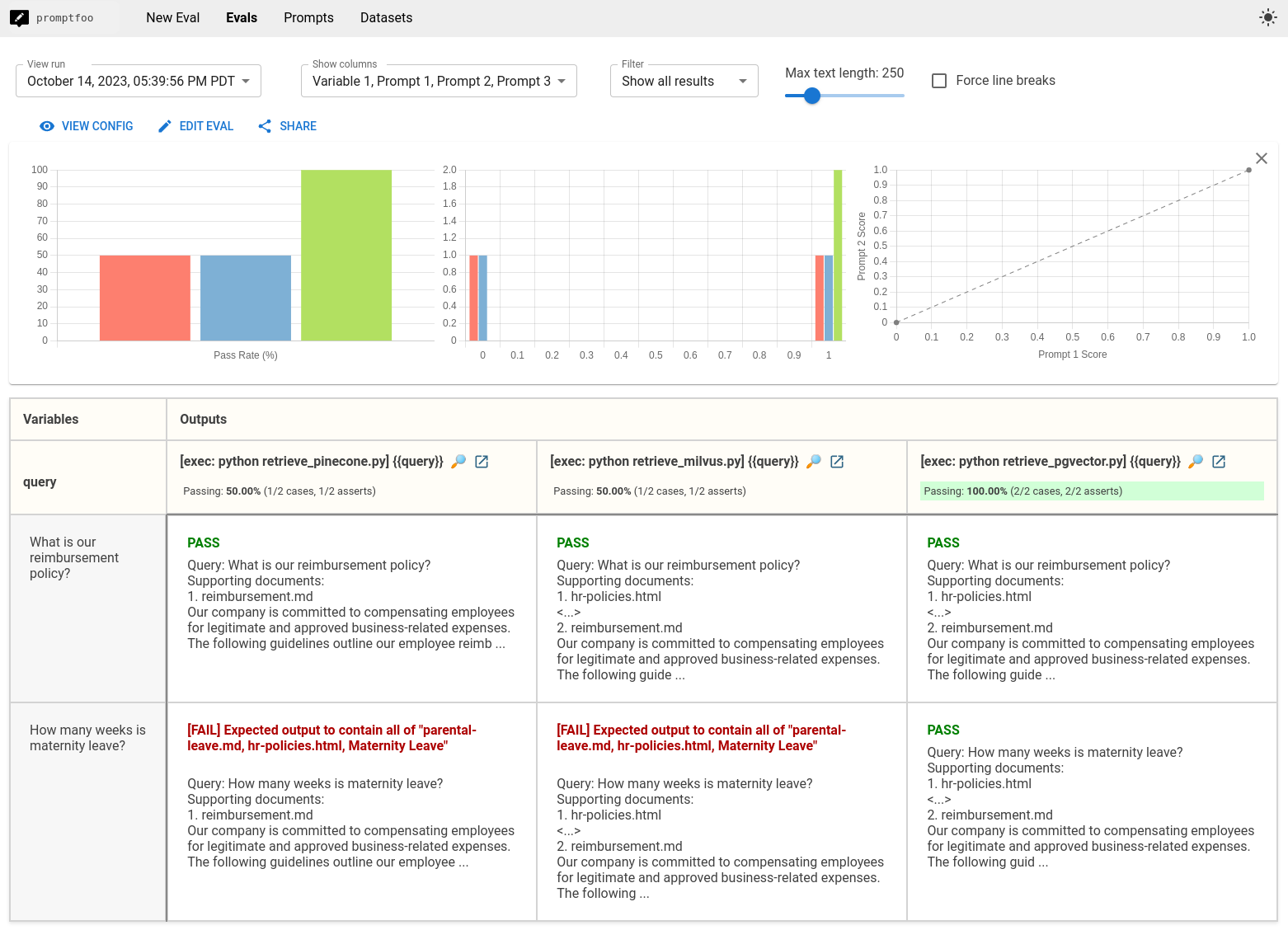
In this particular example, the metrics that we set up indicate that PGVector performs the best. But results will vary based on how you tune the database and how you format or transform the query before sending it to the database.
Evaluating LLM output
Once you are confident that your retrieval step is performing well, it's time to evaluate the LLM itself.
In this step, we are focused on evaluating whether the LLM output is correct given a query and a set of documents.
Instead of using an external script provider, we'll use the built-in functionality for calling LLM APIs. If your LLM output logic is complicated, you can use a python provider as shown above.
First, let's set up our prompt by creating a prompt1.txt file:
You are a corporate intranet chat assistant. The user has asked the following:
<QUERY>
{{ query }}
</QUERY>
You have retrieved some documents to assist in your response:
<DOCUMENTS>
{{ context }}
</DOCUMENTS>
Think carefully and respond to the user concisely and accurately.
Now that we've constructed a prompt, let's set up some test cases. In this example, the eval will format each of these test cases using the prompt template and send it to the LLM API:
prompts: [file://prompt1.txt]
providers: [openai:gpt-5-mini]
tests:
- vars:
query: What is the max purchase that doesn't require approval?
context: file://docs/reimbursement.md
assert:
- type: contains
value: '$500'
- type: factuality
value: the employee's manager is responsible for approvals
- type: answer-relevance
threshold: 0.9
- vars:
query: How many weeks is maternity leave?
context: file://docs/maternity.md
assert:
- type: factuality
value: maternity leave is 4 months
- type: answer-relevance
threshold: 0.9
- type: similar
value: eligible employees can take up to 4 months of leave
In this config, we've assumed the existence of some test fixtures docs/reimbursement.md and docs/maternity.md. You could also just hardcode the values directly in the config.
The factuality and answer-relevance assertions use OpenAI's model-grading prompt to evaluate the accuracy of the output using an LLM. If you prefer deterministic grading, you may use some of the other supported string or regex based assertion types (docs).
The similar assertion uses embeddings to evaluate the relevancy of the RAG output to the expected result.
Using dynamic context
You can define a Python script that fetches context based on other variables in the test case. This is useful if you want to retrieve specific docs for each test case.
Here's how you can modify the promptfooconfig.yaml and create a load_context.py script to achieve this:
- Update the
promptfooconfig.yamlfile:
# ...
tests:
- vars:
question: 'What is the parental leave policy?'
context: file://./load_context.py
- Create the
load_context.pyscript:
def retrieve_documents(question: str) -> str:
# Calculate embeddings, search vector db...
return f'<Documents similar to {question}>'
def get_var(var_name, prompt, other_vars):
question = other_vars['question']
context = retrieve_documents(question)
return {
'output': context
}
# In case of error:
# return {
# 'error': 'Error message'
# }
The load_context.py script defines two functions:
get_var(var_name, prompt, other_vars): This is a special function that promptfoo looks for when loading dynamic variables.retrieve_documents(question: str) -> str: This function takes thequestionas input and retrieves relevant documents based on the question. You can implement your own logic here to search a vector database or do anything else to fetch context.
Run the eval
The promptfoo eval command will run the evaluation and check if your tests are passed. Use the web viewer to view the test output. You can click into a test case to see the full prompt, as well as the test outcomes.
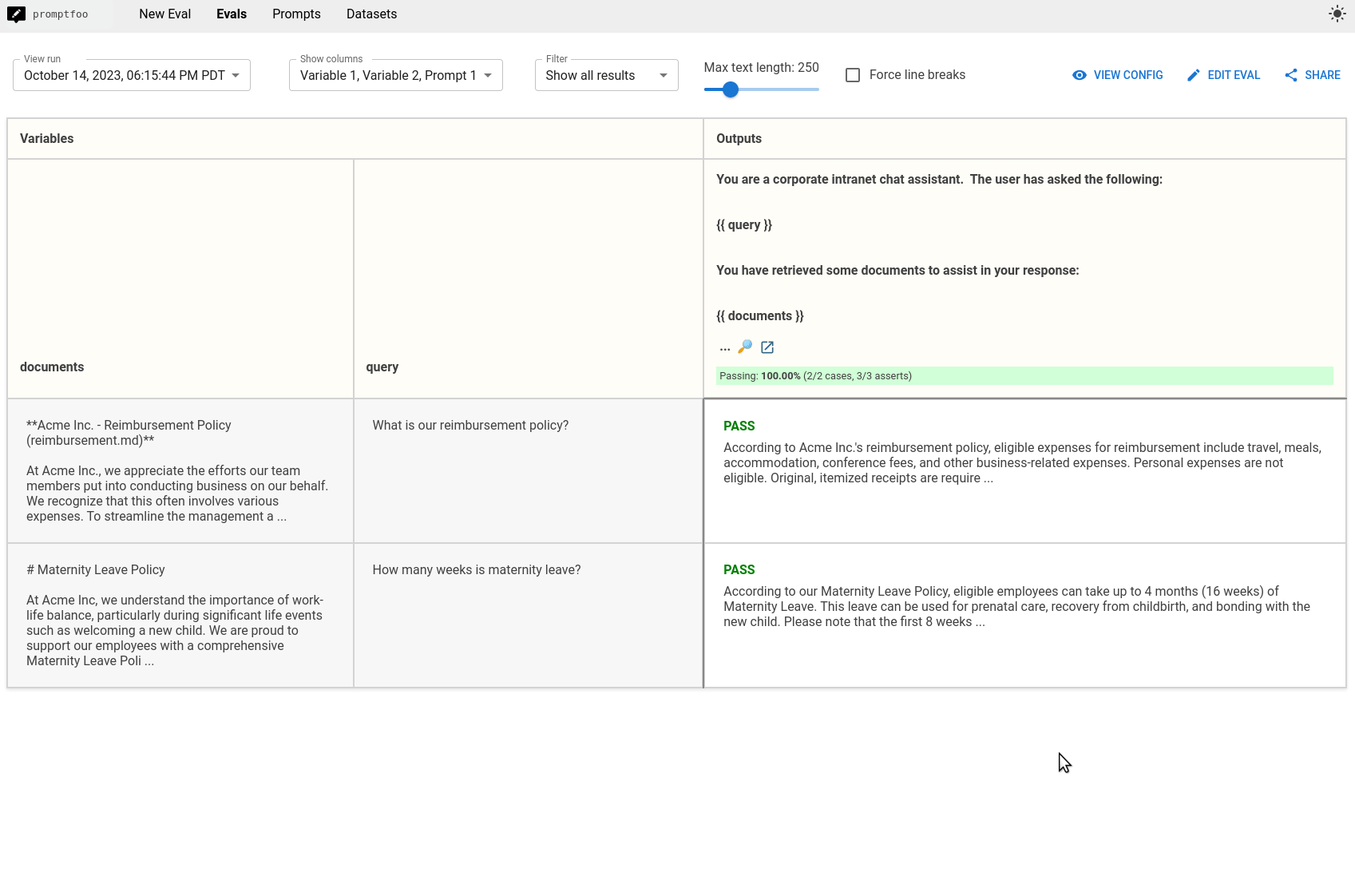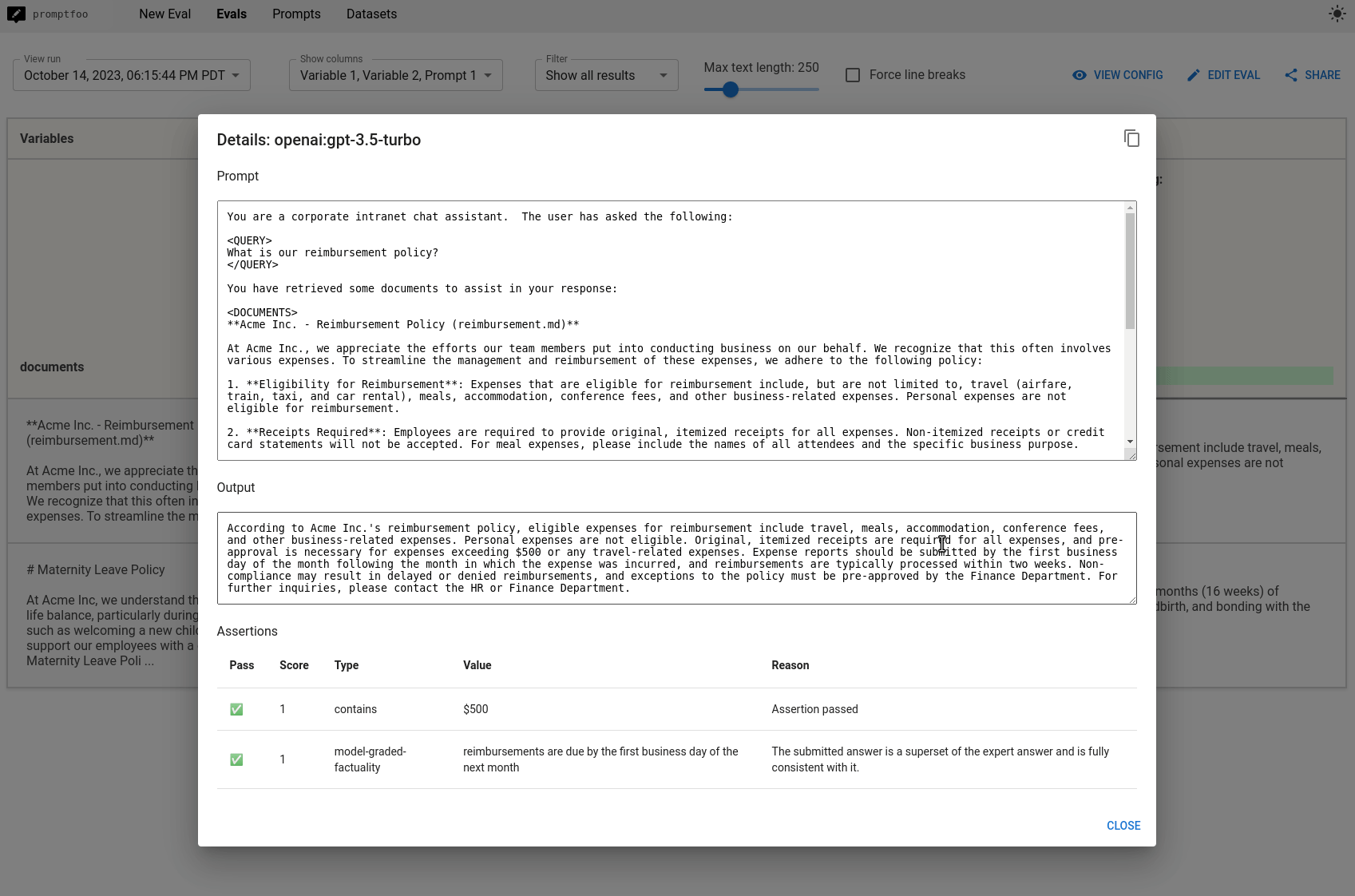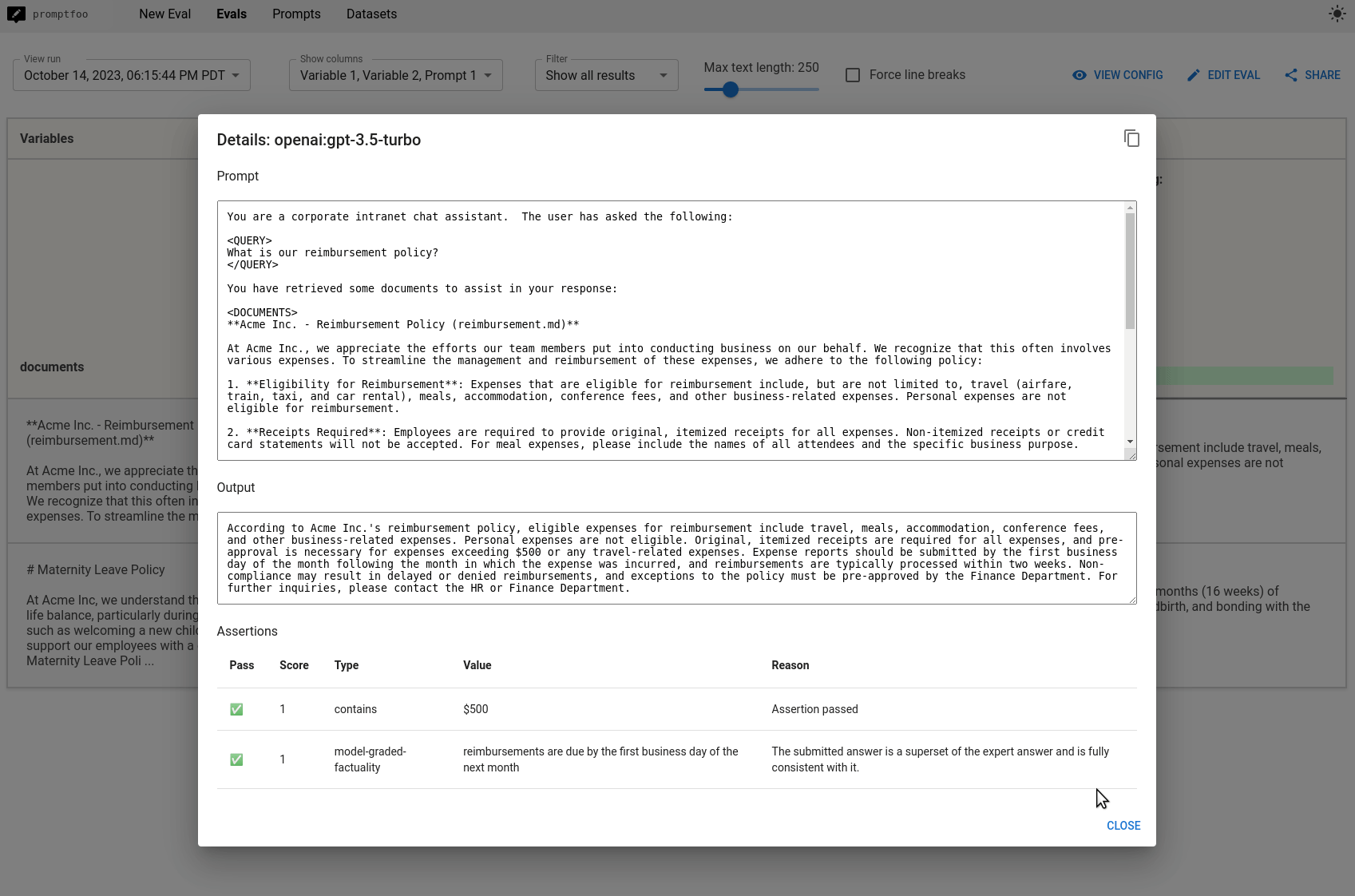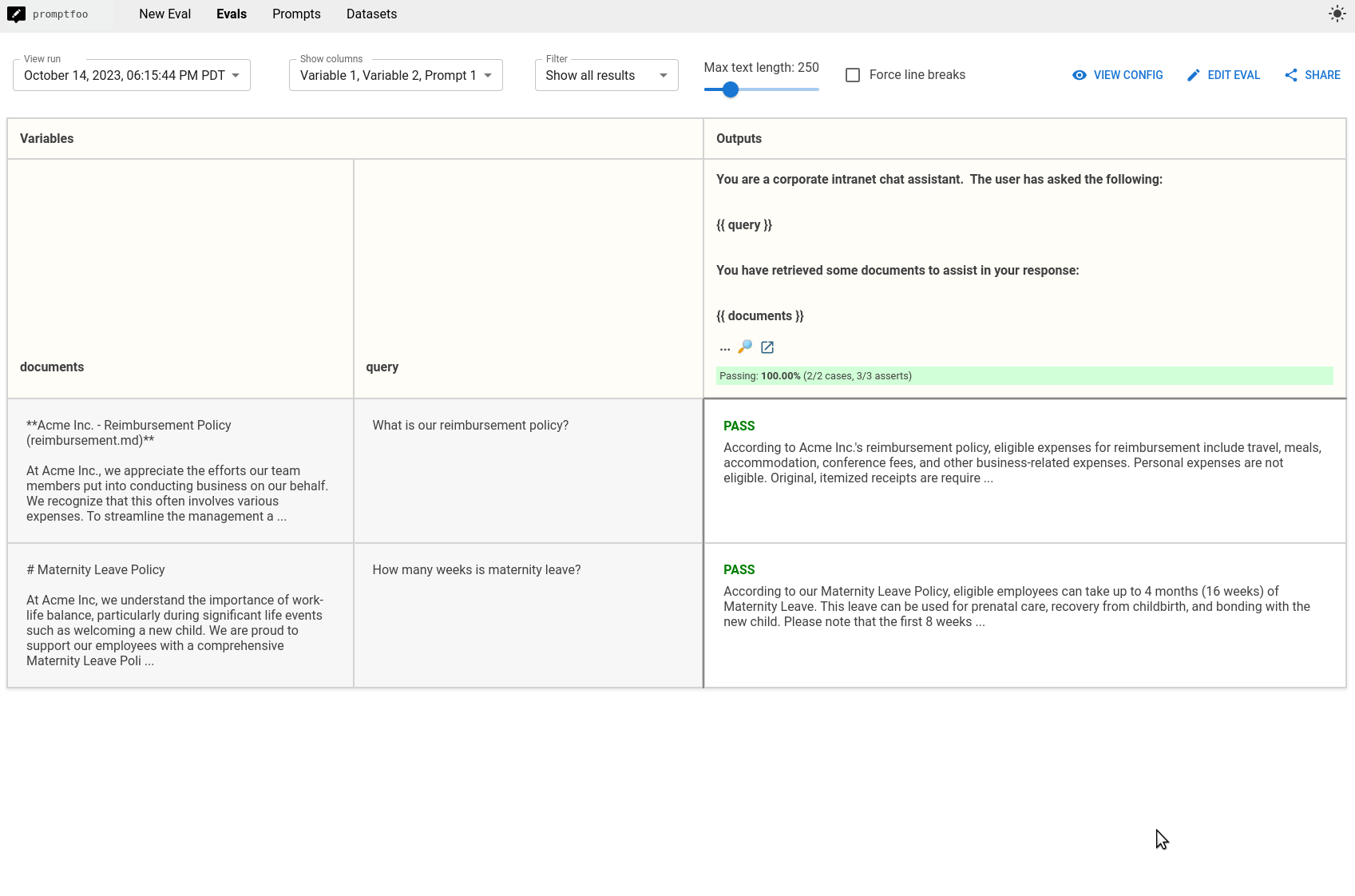
Comparing prompts
Suppose we're not happy with the performance of the prompt above and we want to compare it with another prompt. Maybe we want to require citations. Let's create prompt2.txt:
You are a corporate intranet researcher. The user has asked the following:
<QUERY>
{{ query }}
</QUERY>
You have retrieved some documents to assist in your response:
<DOCUMENTS>
{{ documents }}
</DOCUMENTS>
Think carefully and respond to the user concisely and accurately. For each statement of fact in your response, output a numeric citation in brackets [0]. At the bottom of your response, list the document names for each citation.
Now, update the config to list multiple prompts:
prompts:
- file://prompt1.txt
- file://prompt2.txt
Let's also introduce a metric
The output of promptfoo eval will compare the performance across both prompts, so that you can choose the best one:
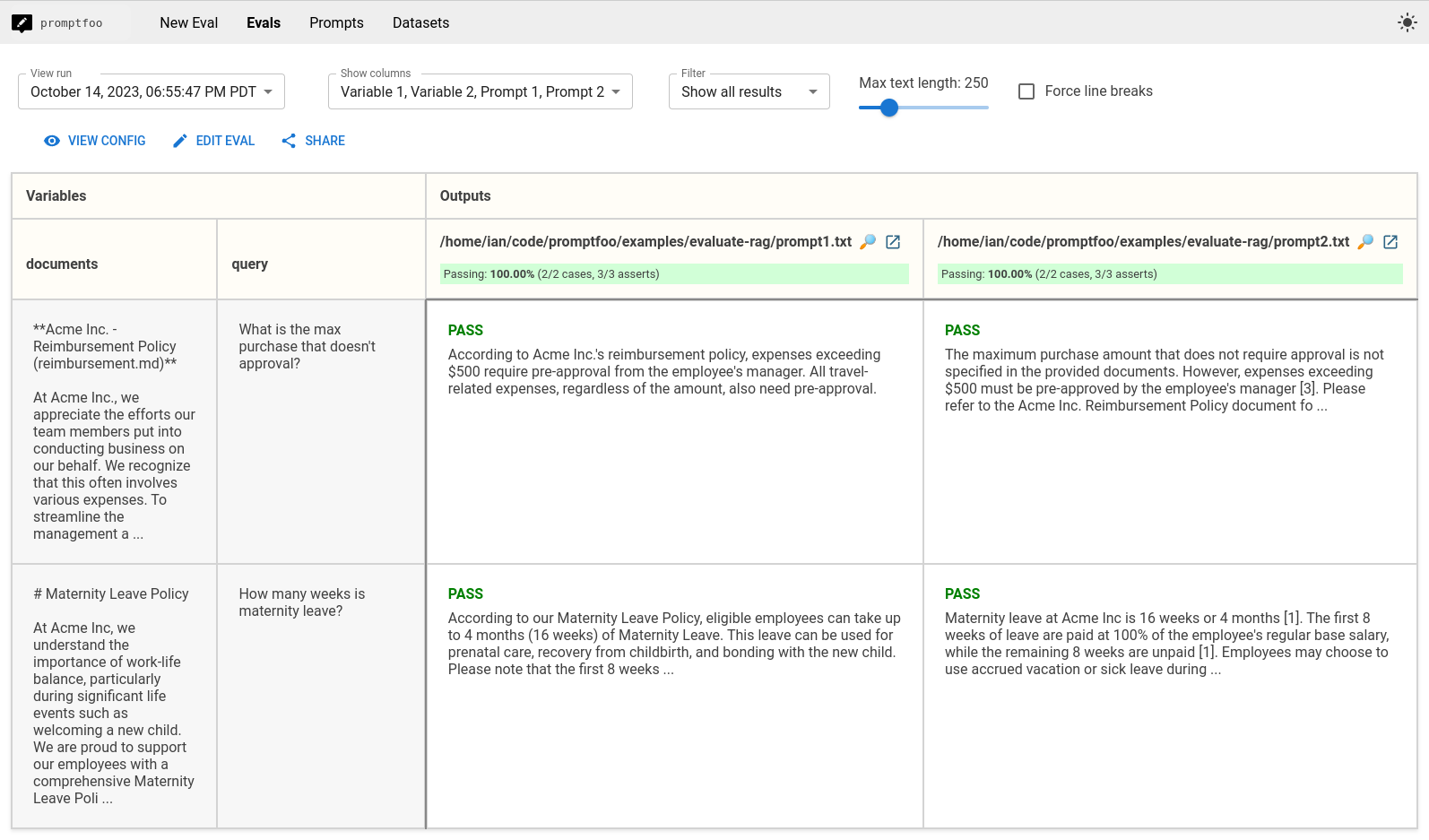
In the above example, both prompts perform well. So we might go with prompt 1, which is shorter and uses fewer tokens.
Comparing models
Imagine we're exploring budget and want to compare the performance of GPT-4 vs Llama. Update the providers config to list each of the models:
providers:
- openai:gpt-5-mini
- openai:gpt-5
- anthropic:claude-sonnet-4-6
- ollama:chat:llama4:scout
Let's also add a heuristic that prefers shorter outputs. Using the defaultTest directive, we apply this to all RAG tests:
defaultTest:
assert:
- type: python
value: max(0, min(1, 1 - (len(output) - 100) / 900))
Here's the final config:
prompts: [file://prompt1.txt]
providers: [openai:gpt-5-mini, openai:gpt-5, ollama:chat:llama4:scout]
defaultTest:
assert:
- type: python
value: max(0, min(1, 1 - (len(output) - 100) / 900))
tests:
- vars:
query: What is the max purchase that doesn't require approval?
context: file://docs/reimbursement.md
assert:
- type: contains
value: '$500'
- type: factuality
value: the employee's manager is responsible for approvals
- type: answer-relevance
threshold: 0.9
- vars:
query: How many weeks is maternity leave?
context: file://docs/maternity.md
assert:
- type: factuality
value: maternity leave is 4 months
- type: answer-relevance
threshold: 0.9
- type: similar
value: eligible employees can take up to 4 months of leave
The output shows how each model performs on your test cases, making it easy to spot differences:
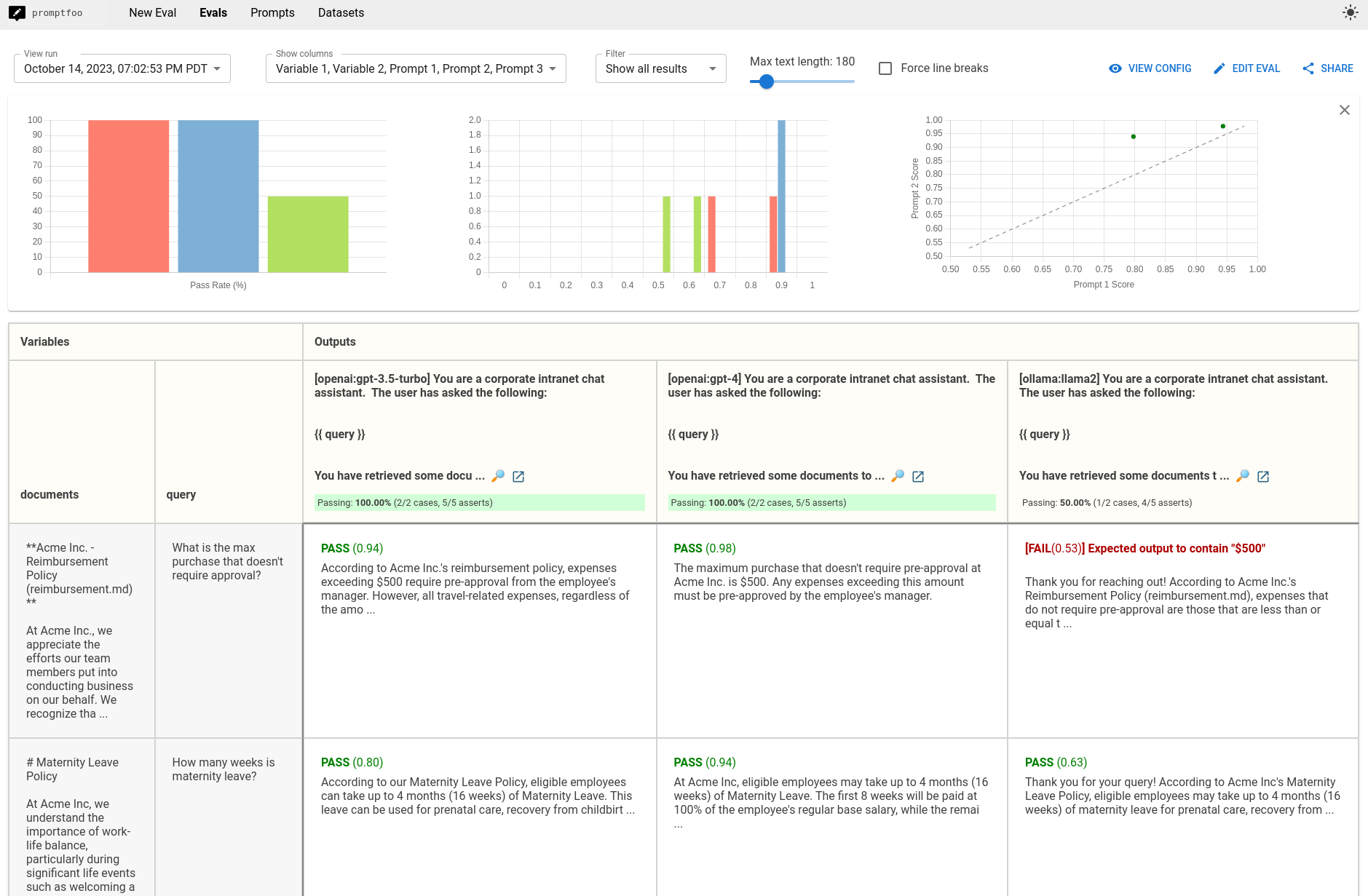
Remember, evals are what you make of them - you should always develop test cases that focus on the metrics you care about.
Evaluating end-to-end performance
We've covered how to test the retrieval and generation steps separately. You might be wondering how to test everything end-to-end.
The way to do this is similar to the "Evaluating document retrieval" step above. You'll have to create a script that performs document retrieval and calls the LLM, then set up a config like this:
# Test different prompts to find the best
prompts: [file://prompt1.txt, file://prompt2.txt]
# Test different retrieval and generation methods to find the best
providers:
- file://retrieve_and_generate_v1.py
- file://retrieve_and_generate_v2.py
tests:
# ...
By following this approach and setting up tests on assertions & metrics, you can ensure that the quality of your RAG pipeline is improving, and prevent regressions.
See the RAG example on GitHub for a fully functioning end-to-end example.
Context evaluation approaches
There are two ways to provide context for RAG evaluation:
Context variables approach
Use this when you have separate context data or want explicit control over what context is used:
tests:
- vars:
query: 'What is the capital of France?'
context: 'France is a country in Europe. Paris is the capital and largest city of France.'
assert:
- type: context-faithfulness
threshold: 0.8
- type: context-relevance
threshold: 0.7
- type: context-recall
value: 'Expected information to verify'
threshold: 0.8
Response extraction approach
Use this when your RAG system returns context alongside the generated response:
assert:
- type: context-faithfulness
contextTransform: 'output.context'
threshold: 0.8
- type: context-relevance
contextTransform: 'output.context'
threshold: 0.7
- type: context-recall
contextTransform: 'output.context'
value: 'Expected information to verify'
threshold: 0.8
The contextTransform and options.transform both receive the provider's output directly. This ensures that context extraction works reliably even when the main output is transformed for other assertions.
For example, if you have:
options:
transform: 'output.answer' # Extract just the answer for assertions
assert:
- type: context-faithfulness
contextTransform: 'output.documents' # Still has access to documents
Both transforms receive the full response object, allowing independent extraction of answer and context.
For complex response structures, you can use JavaScript expressions:
assert:
- type: context-faithfulness
contextTransform: 'output.retrieved_docs.map(d => d.content).join("\n")'
- type: context-relevance
contextTransform: 'output.sources.filter(s => s.relevance > 0.7).map(s => s.text).join("\n\n")'
Common patterns
# Extract from array of objects
contextTransform: 'output.documents.map(d => d.content).join("\n")'
# Handle missing data with fallback
contextTransform: 'output.context || output.retrieved_content || "No context"'
# Extract from nested metadata (e.g., AWS Bedrock Knowledge Base)
contextTransform: 'output.citations?.[0]?.content?.text || ""'
For more examples, see the AWS Bedrock Knowledge Base documentation and context assertion reference.
Multi-lingual RAG Evaluation
Multi-lingual RAG systems are increasingly common in global applications where your knowledge base might be in one language (e.g., English documentation) but users ask questions in their native language (e.g., Spanish, Japanese, Arabic). This creates unique evaluation challenges that require careful metric selection.
Understanding Cross-lingual Challenges
When documents and queries are in different languages, traditional evaluation metrics can fail dramatically. The key distinction is between metrics that evaluate conceptual relationships versus those that rely on textual matching.
For example, if your context says "Solar energy is clean" in Spanish ("La energía solar es limpia") and your expected answer is "Solar power is environmentally friendly" in English, a text-matching metric will see zero similarity despite the semantic equivalence.
Metrics That Work Cross-lingually
These metrics evaluate meaning rather than text, making them suitable for cross-lingual scenarios:
context-relevance (Best performer: 85-95% accuracy)
This metric asks: "Is the retrieved context relevant to the query?" Since relevance is a conceptual relationship, it transcends language barriers. An LLM can determine that Spanish text about "energía solar" is relevant to an English question about "solar energy."
context-faithfulness (70-80% accuracy)
This checks whether the answer only uses information from the provided context. LLMs can trace information across languages - they understand that facts extracted from Spanish documents and presented in English answers still maintain faithfulness to the source.
answer-relevance (65-75% accuracy)
Evaluates whether the answer addresses the question, regardless of the languages involved. The semantic relationship between question and answer remains evaluable across languages. Note: When context and query are in different languages, the LLM may respond in either language, which can affect this metric's score.
llm-rubric (Highly flexible)
Allows you to define custom evaluation criteria that explicitly handle cross-lingual scenarios. This is your Swiss Army knife for specialized requirements.
Metrics to Avoid for Cross-lingual
These metrics fail when languages don't match:
context-recall (Drops from 80% to 10-30% accuracy)
This metric attempts to verify that the context contains specific expected information by matching text. When your expected answer is "The capital is Paris" but your context says "La capital es París," the metric fails to recognize the match. Use llm-rubric instead to check for concept coverage.
String-based metrics (Levenshtein, ROUGE, BLEU)
These traditional NLP metrics measure surface-level text similarity - comparing characters, words, or n-grams. They have no understanding that "dog" and "perro" mean the same thing. They'll report near-zero similarity for semantically identical content in different languages.
Practical Configuration
Here's how to configure cross-lingual evaluation effectively.
When context and query are in different languages, LLMs may respond in either language. This affects metrics like answer-relevance. To control this, explicitly specify the output language in your prompt (e.g., "Answer in English").
# Cross-lingual evaluation (e.g., English queries, Spanish documents)
tests:
- vars:
query: 'What are the benefits of solar energy?'
# Context is in Spanish while query is in English
context: |
La energía solar ofrece numerosos beneficios.
Produce energía limpia sin emisiones.
Los costos operativos son muy bajos.
Proporciona independencia energética.
assert:
# These metrics work well cross-lingually
- type: context-relevance
threshold: 0.85 # Stays high because it evaluates concepts, not text
- type: context-faithfulness
threshold: 0.70 # Reduced from 0.90 baseline due to cross-lingual processing
- type: answer-relevance
threshold: 0.65 # Lower threshold when answer language may differ from query
# DON'T use context-recall for cross-lingual
# Instead, use llm-rubric to check for specific concepts
- type: llm-rubric
value: |
Check if the answer correctly uses information about:
1. Clean energy without emissions
2. Low operational costs
3. Energy independence
Score based on coverage of these points.
threshold: 0.75