Mixtral vs GPT: Run a benchmark with your own data
In this guide, we'll walk through the steps to compare three large language models (LLMs): Mixtral, GPT-5-mini, and GPT-5. We will use promptfoo, a command-line interface (CLI) tool, to run evaluations and compare the performance of these models based on a set of prompts and test cases.
Requirements
promptfooCLI installed on your system.- Access to Replicate for Mixtral.
- Access to OpenAI for GPT-5-mini and GPT-5.
- API keys for Replicate (
REPLICATE_API_TOKEN) and OpenAI (OPENAI_API_KEY).
Step 1: Initial Setup
Create a new directory for your comparison project:
mkdir mixtral-gpt-comparison
cd mixtral-gpt-comparison
Step 2: Configure the models
Create a promptfooconfig.yaml with the models you want to compare. Here's an example configuration with Mixtral, GPT-5-mini, and GPT-5:
providers:
- replicate:mistralai/mixtral-8x22b-instruct-v0.1
- openai:gpt-5-mini
- openai:gpt-5
Set your API keys as environment variables:
export REPLICATE_API_TOKEN=your_replicate_api_token
export OPENAI_API_KEY=your_openai_api_key
In this example, we're using Replicate, but you can also use providers like HuggingFace, TogetherAI, etc:
- huggingface:text-generation:mistralai/Mistral-7B-Instruct-v0.3
- id: openai:chat:mistralai/Mixtral-8x22B-Instruct-v0.1
config:
apiBaseUrl: https://api.together.xyz/v1
Local options such as ollama, vllm, and localai also exist. See providers for all options.
Optional: Configure model parameters
Customize the behavior of each model by setting parameters such as max_tokens or max_length:
providers:
- id: openai:gpt-5-mini
config:
max_tokens: 128
- id: openai:gpt-5
config:
max_tokens: 128
- id: replicate:mistralai/mixtral-8x22b-instruct-v0.1
config:
temperature: 0.01
max_new_tokens: 128
Step 3: Set up your prompts
Set up the prompts that you want to run for each model. In this case, we'll just use a simple prompt, because we want to compare model performance.
prompts:
- 'Answer this as best you can: {{query}}'
If desired, you can test multiple prompts (just add more to the list), or test different prompts for each model.
Step 4: Add test cases
Define the test cases that you want to use for the evaluation. This includes setting up variables that will be interpolated into the prompts:
tests:
- vars:
query: 'What is the capital of France?'
assert:
- type: contains
value: 'Paris'
- vars:
query: 'Explain the theory of relativity.'
assert:
- type: contains
value: 'Einstein'
- vars:
query: 'Write a poem about the sea.'
assert:
- type: llm-rubric
value: 'The poem should evoke imagery such as waves or the ocean.'
- vars:
query: 'What are the health benefits of eating apples?'
assert:
- type: contains
value: 'vitamin'
- vars:
query: "Translate 'Hello, how are you?' into Spanish."
assert:
- type: similar
value: 'Hola, ¿cómo estás?'
- vars:
query: 'Output a JSON list of colors'
assert:
- type: is-json
- type: latency
threshold: 5000
Optionally, you can set up assertions to automatically assess the output for correctness.
Step 5: Run the comparison
With everything configured, run the evaluation using the promptfoo CLI:
npx promptfoo@latest eval
This command will execute each test case against each configured model and record the results.
To visualize the results, use the promptfoo viewer:
npx promptfoo@latest view
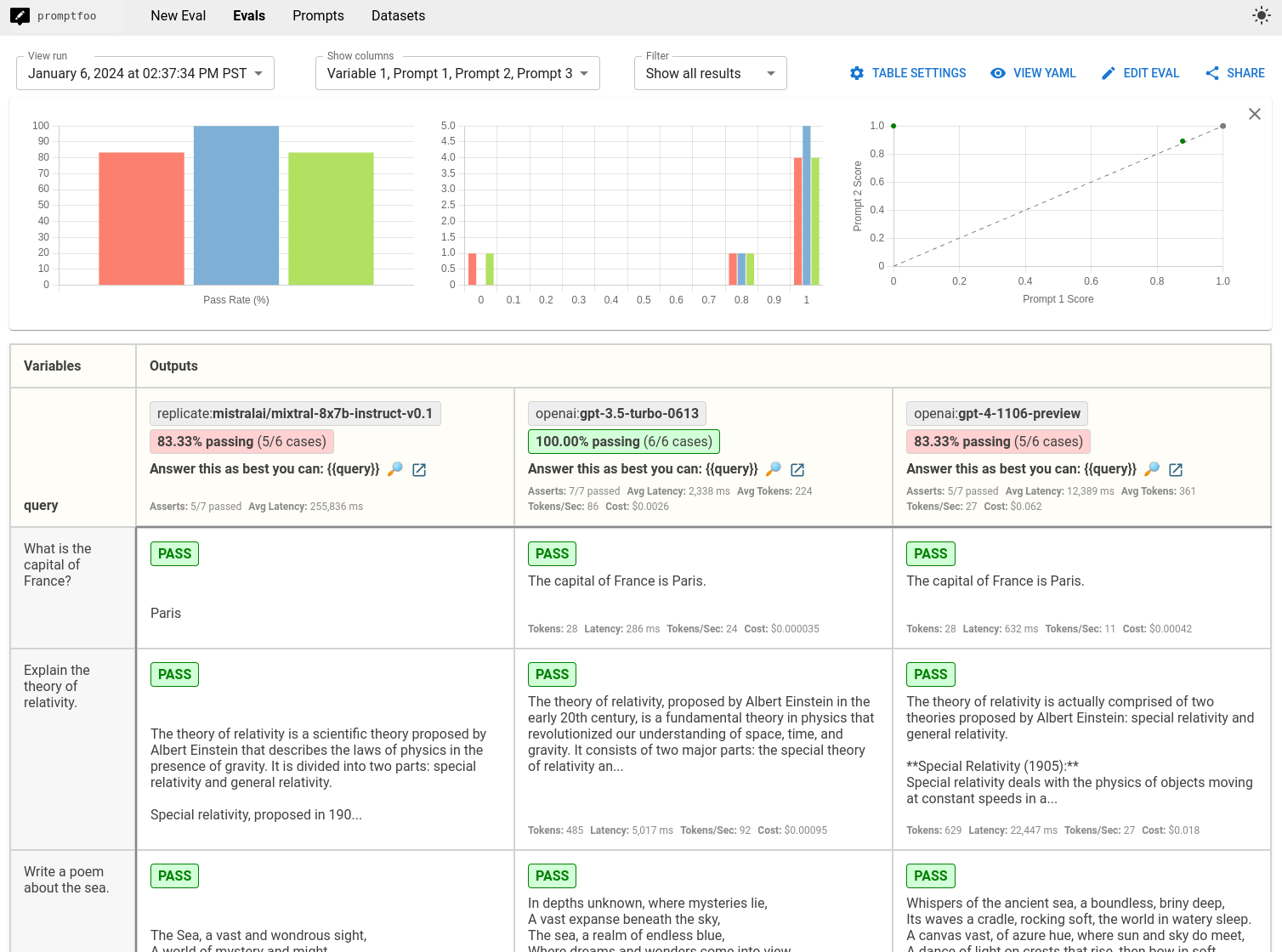
It will show results like so:
You can also output the results to a file in various formats, such as JSON, YAML, or CSV:
npx promptfoo@latest eval -o results.csv
Conclusion
The comparison will provide you with a side-by-side performance view of Mixtral, GPT-5-mini, and GPT-5 based on your test cases. Use this data to make informed decisions about which LLM best suits your application.
While public benchmarks like Arena tell you how these models perform on generic tasks, they are no substitute for running a benchmark on your own data and use cases.
The examples above highlighted a few cases where GPT outperforms Mixtral: notably, GPT-5 was better at following JSON output instructions. But, GPT-5-mini had the highest eval score because of the latency requirements that we added to one of the test cases. Overall, the best choice is going to depend largely on the test cases that you construct and your own application constraints.