Phi vs Llama: Benchmark on your own data
When choosing between LLMs like Phi 3 and Llama 3.1, it's important to benchmark them on your specific use cases rather than relying solely on public benchmarks. When models are in the same ballpark, the specific application makes a big difference.
This guide walks you through the steps to set up a comprehensive benchmark of Llama and Phi using promptfoo + Ollama.
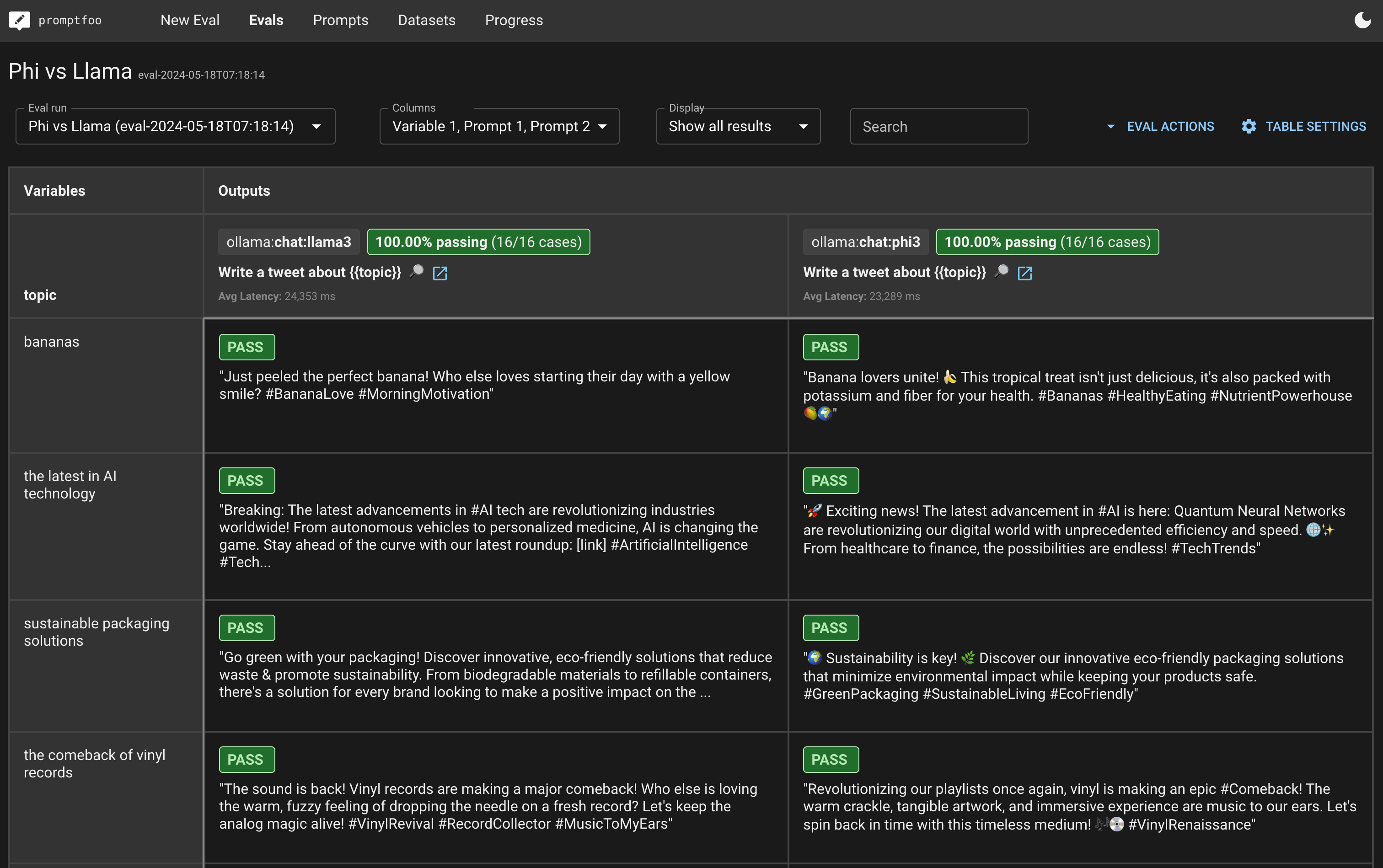
In the end, you'll be able to create a side-by-side evaluation view that looks like this:
Requirements
Before starting, ensure you have the following:
promptfooinstalled (see installation guide)- Ollama set up and running (see Ollama documentation)
- Your Ollama API base URL and port (default is
http://localhost:11434)
Step 1: Initialize
First, create a new directory for your benchmark:
npx promptfoo@latest init phi-vs-llama
cd phi-vs-llama
Step 2: Configure
Open promptfooconfig.yaml and set up the models you want to compare. We'll use the ollama:chat:phi3 and ollama:chat:llama3 endpoints.
Define prompts
Start by defining the prompts you will use for testing. In this example, we're just going to pass through a single message variable:
prompts:
- '{{message}}'
Configure providers
Next, specify the models and their configurations:
prompts:
- '{{message}}'
providers:
- id: ollama:chat:phi3
config:
temperature: 0.01
num_predict: 128
- id: ollama:chat:llama3.1
config:
temperature: 0.01
num_predict: 128
Step 3: Build a test set
Test cases should be representative of your application's use cases. Here are some example test cases:
tests:
- vars:
message: 'Tell me a joke.'
- vars:
message: 'What is the capital of France?'
- vars:
message: 'Explain the theory of relativity in simple terms.'
- vars:
message: 'Translate "Good morning" to Spanish.'
- vars:
message: 'What are the benefits of a healthy diet?'
- vars:
message: 'Write a short story about a dragon and a knight.'
Add assertions (optional)
You can add automated checks with the assert property in order to automatically make sure the outputs are correct.
tests:
- vars:
message: 'Tell me a joke.'
assert:
- type: llm-rubric
value: Contains a setup and a punch line.
- vars:
message: 'What is the capital of France?'
assert:
- type: icontains
value: Paris
- vars:
message: 'Explain the theory of relativity in simple terms.'
assert:
- type: llm-rubric
value: Simplifies complex concepts
- vars:
message: 'Translate "Good morning" to Spanish.'
assert:
- type: icontains
value: Buenos días
- vars:
message: 'What are the benefits of a healthy diet?'
assert:
- type: llm-rubric
value: Lists health benefits
- vars:
message: 'Write a short story about a dragon and a knight.'
assert:
- type: llm-rubric
value: Creative storytelling
Step 4: Run the benchmark
Execute the comparison using the following command:
npx promptfoo@latest eval
Then, view the results:
npx promptfoo@latest view
This will open a web viewer showing a side-by-side comparison of the models' performance. It will look something like this (the exact appearance will vary based on your test cases and scoring mechanisms):
Step 5: Analyze the results
After running the evaluation, analyze the results to determine which model performs best for your specific use cases. Look for patterns in the output, such as accuracy, creativity, and adherence to the prompt.
For more detailed information on setting up and running benchmarks, refer to the Getting Started guide and the Ollama documentation.