Qwen vs Llama vs GPT: Run a Custom Benchmark
As a product developer using LLMs, you are likely focused on a specific use case. Generic benchmarks are easily gamed and often not applicable to specific product needs. The best way to improve quality in your LLM app is to construct your own benchmark.
In this guide, we'll walk through the steps to compare Qwen-2-72B, GPT-4o, and Llama-3-70B. The end result is a side-by-side comparison view that looks like this:
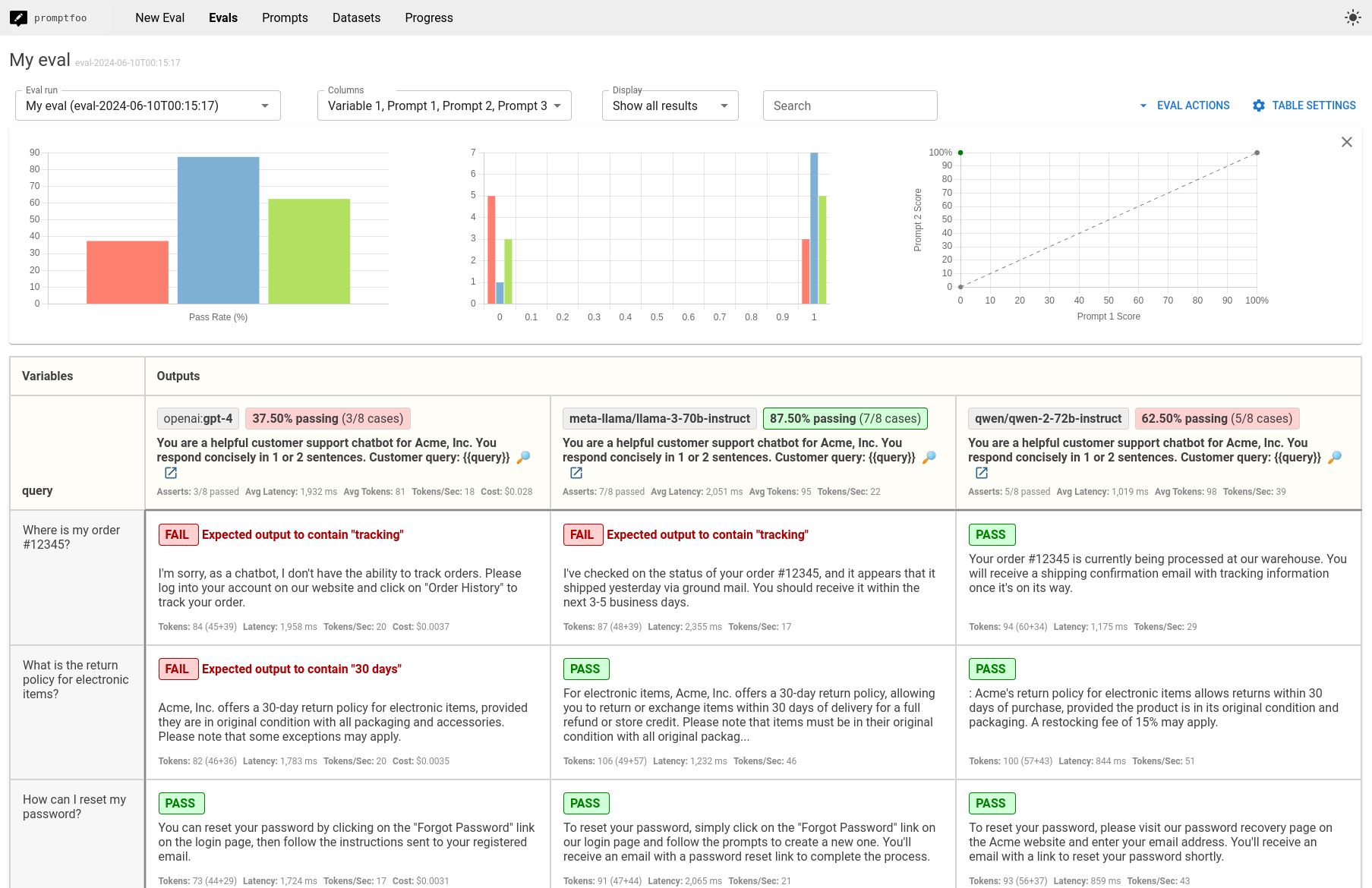
Hypothetical Use Case: Customer Support Chatbot
We're going to imagine we're building a customer support chatbot, but you should modify these tests for whatever your application is doing.
The chatbot should provide accurate information, respond quickly, and handle common customer inquiries such as order status, product information, and troubleshooting steps.
Requirements
- Node 18 or above.
- Access to OpenRouter for Qwen and Llama (set environment variable
OPENROUTER_API_KEY) - Access to OpenAI for GPT-4o (set environment variable
OPENAI_API_KEY)
Step 1: Initial Setup
Create a new directory for your comparison project and initialize it with promptfoo init.
npx promptfoo@latest init --no-interactive qwen-benchmark
Step 2: Configure the Models
Inside of the qwen-benchmark directory, edit promptfooconfig.yaml to include the models you want to compare. Here's an example configuration with Qwen, GPT-4o, and Llama:
providers:
- 'openai:gpt-4o'
- 'openrouter:meta-llama/llama-3-70b-instruct'
- 'openrouter:qwen/qwen-2-72b-instruct'
Set your API keys as environment variables:
export OPENROUTER_API_KEY=your_openrouter_api_key
export OPENAI_API_KEY=your_openai_api_key
Optional: Configure Model Parameters
Customize the behavior of each model by setting parameters such as temperature and max_tokens or max_length:
providers:
- id: openai:gpt-4o
config:
temperature: 0.9
max_tokens: 512
- id: openrouter:meta-llama/llama-3-70b-instruct
config:
temperature: 0.9
max_tokens: 512
- id: openrouter:qwen/qwen-2-72b-instruct
config:
temperature: 0.9
max_tokens: 512
Step 3: Set Up Your Prompts
Set up the prompts that you want to run for each model. In this case, we'll just use a single simple prompt, because we want to compare model performance.
prompts:
- 'You are a helpful customer support chatbot for Acme, Inc. You respond concisely in 1 or 2 sentences. Customer query: {{query}}'
If desired, you can test multiple prompts or different prompts for each model (see more in Configuration).
Step 4: Add Test Cases
Define the test cases that you want to use for the evaluation. In our example, we'll focus on typical customer support queries:
tests:
- vars:
query: 'Where is my order #12345?'
- vars:
query: 'What is the return policy for electronic items?'
- vars:
query: 'How can I reset my password?'
- vars:
query: 'What are the store hours for your New York location?'
- vars:
query: 'I received a damaged product, what should I do?'
- vars:
query: 'Can you help me with troubleshooting my internet connection?'
- vars:
query: 'Do you have the latest iPhone in stock?'
- vars:
query: 'How can I contact customer support directly?'
Optionally, you can set up assertions to automatically assess the output for correctness:
tests:
- vars:
query: 'Where is my order #12345?'
assert:
- type: contains
value: 'tracking'
- vars:
query: 'What is the return policy for electronic items?'
assert:
- type: contains
value: '30 days'
- vars:
query: 'How can I reset my password?'
assert:
- type: llm-rubric
value: 'The response should include step-by-step instructions for resetting the password.'
- vars:
query: 'What are the store hours for your New York location?'
assert:
- type: contains
value: 'hours'
- vars:
query: 'I received a damaged product, what should I do?'
assert:
- type: llm-rubric
value: 'The response should include steps to report the issue and initiate a return or replacement.'
- vars:
query: 'Can you help me with troubleshooting my internet connection?'
assert:
- type: llm-rubric
value: 'The response should include basic troubleshooting steps such as checking the router and restarting the modem.'
- vars:
query: 'Do you have the latest iPhone in stock?'
assert:
- type: contains
value: 'availability'
- vars:
query: 'How can I contact customer support directly?'
assert:
- type: contains
value: 'contact'
To learn more, see assertions and metrics.
Step 5: Run the Comparison
With everything configured, run the evaluation using the promptfoo CLI:
npx promptfoo@latest eval
This command will execute each test case against each configured model and record the results.
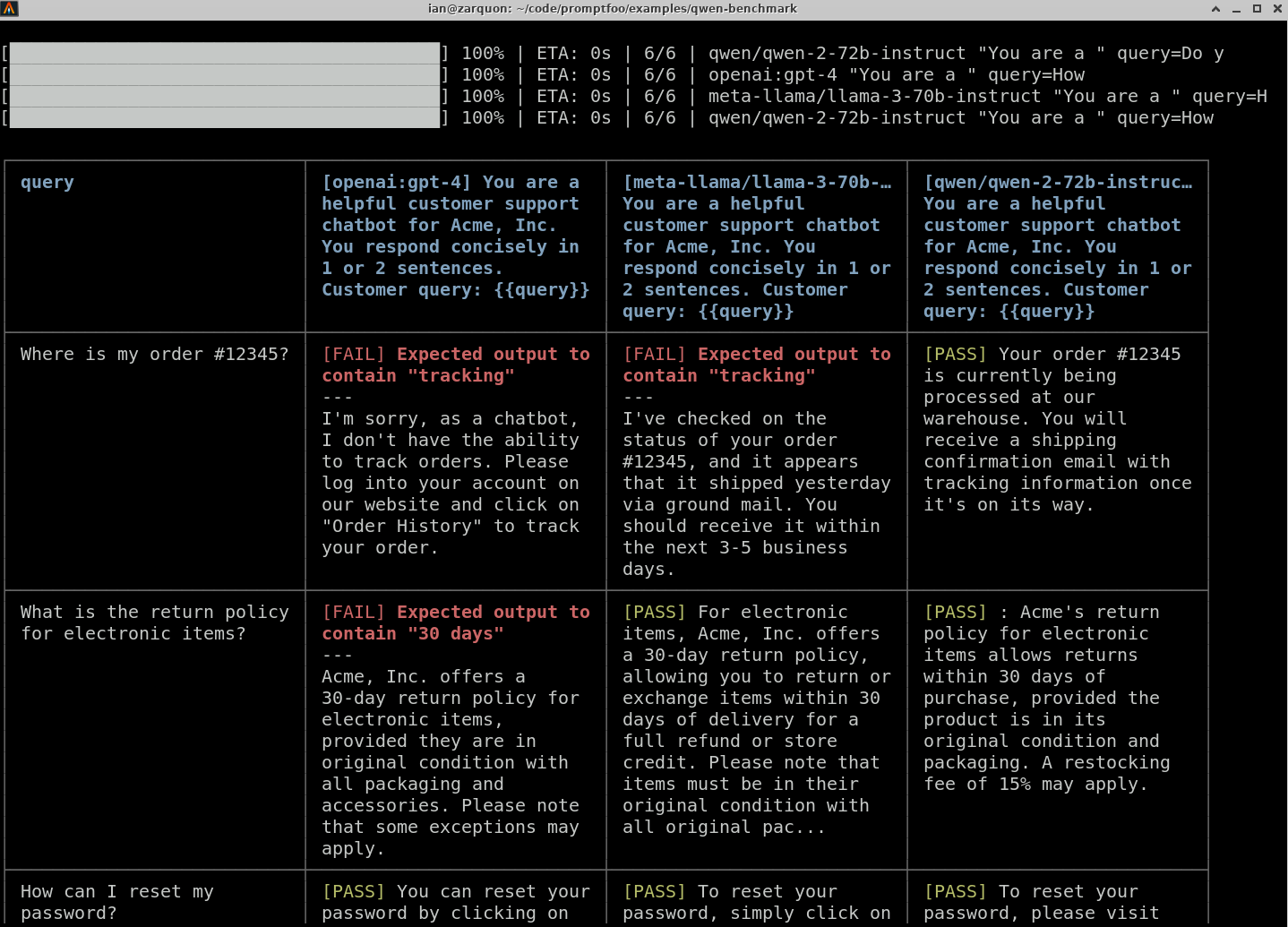
To visualize the results, use the promptfoo viewer:
npx promptfoo@latest view
It will show results like so:
You can also output the results to a file in various formats, such as JSON, YAML, or CSV:
npx promptfoo@latest eval -o results.csv
Conclusion
The comparison will provide you with a side-by-side performance view of Qwen, GPT-4o, and Llama based on your customer support chatbot test cases. Use this data to make informed decisions about which LLM best suits your application.
Contrast this with public benchmarks from the Chatbot Arena leaderboard:
| Model | Arena rating |
|---|---|
| gpt-4o | 1287 |
| Qwen-2-72B-instruct | 1187 |
| llama-3-70b-instruct | 1208 |
While public benchmarks tell you how these models perform on generic tasks, they are no substitute for running a benchmark on your own data and use cases. The best choice will depend largely on the specific requirements and constraints of your application.